Metadata Governance Day¶
As metadata is shared and linked, the gaps and inconsistencies in it are exposed. In the dojo you will learn how to set up a variety of features in Egeria to actively govern and maintain your metadata environment.
The dojo sessions are colour-coded like ski runs:
Beginner session
Intermediate session
Advanced session
Expert session
As you progress through the dojo, the colors of the sessions show how advanced your knowledge is becoming. The later sections are not necessarily harder to understand, but they build on knowledge from earlier sections.
The schedule also includes estimated times needed to complete each session. Even though a dojo is styled as a "day of intense focus", there is a lot of information conveyed, and you may find it more profitable to only complete one session in each sitting. Whichever way you choose to tackle the dojo, have fun and good luck - and do take breaks whenever you need to!
Metadata Governance Dojo starts here
The importance of metadata governance (25 mins)
The importance of metadata governance¶
Data, and the metadata that describes it, enables individuals and automated processes to make decisions. As the trust grows in the availability, accuracy, timeliness, usefulness and completeness of the data/metadata, its use increases and your organization sees greater value.
Building trust¶
Trust is hard to build and easy to destroy. Maintaining trust begins with authoritative sources of data/metadata that are actively managed and distributed along well known information supply chains. This flow needs to be transparent and reliable - that is, explicitly defined and verifiable through monitoring, inspection, testing and remediation. It needs to be tailored to meet the specific needs of its consumers.
Consider this story ...
A tale about trust
Sam bought a new house in a little village that was 10 miles from where he worked. He is keen to live sustainably and was delighted to hear from his new neighbours that there was a good bus service that many of them used to get to work.
Sam stopped by the bus stop to look up the bus times for the next day.
Next morning he left in plenty of time. He was surprised there was no-one there waiting for the bus. No bus came for nearly an hour, making him late for work. He asked the driver what happened to the earlier bus. He said he was not aware there was any problem.
Once at work he called the bus company. The clerk who answered the phone laughed and said that the timetable at the bus stop was out of date. The local council required them to display a timetable so the one that was there was from last year. It was ok because everyone knew the timetable.
Annoyed, Sam asked where he could get an up-to-date timetable for the bus. The clerk did not know but suggested he call head office and was nice enough to give him with the telephone number. It took a number of calls to find the right person, who then willingly dictated the times to him. Sam asked how often the bus times changed and how he could keep up-to-date. He was told that changes occurred infrequently and when they did, the bus driver would announce it. Sam could also ring back to check for changes from time to time.
Is there any problem with the way that the bus company is operating? How confident do you think Sam is that the bus company will provide a reliable service to get him to work every day? What is the impact if Sam buys a car or uses a bike because he decides the bus company is not to be trusted?
Some thoughts on the case ...
Sam is likely to conclude that the bus company does not care about its customers - and is not focused on attracting new business by encouraging people to try new routes. This suggests it is doomed in the long run. If he misses the bus again because the bus times change then he is motivated to look for alternative solutions.
His perception of the quality of the bus service is as much affected by the quality of information about the buses as the actual frequency and reliability of the service itself.
If we translate this story to the digital world, organizations often provide shared services and/or data sets that other parts of the business rely on. It is not sufficient that these services/data sets are useful with high availability/quality. If potential consumers can not find out about them, or existing consumers are disrupted by unexpected change, then the number of consumers will dwindle as they seek their own solutions, and the shared service looses relevance to the business.
The team providing the shared service should consider the documentation about it to be a key part of their deliverables. Capturing this documentation as metadata and publishing it to the open metadata ecosystem increases its findability and comprehensibility.
Meanwhile, back at the bus company ...
The managing director hears of Sam's experience and wants to understand how widespread a problem it is. She discovers that no-one is specifically responsible for keeping the timetables up-to-date at the bus stops, or ensuring up-to-date timetables are available for download/pick up. She discovered a few conscientious souls that update the bus timetable at the bus stops they personally use. However, across their network, the information supplied at the bus stops was misleading because it was out-of-date.
It is often the case that if something is not being done, either:
- no-one is responsible for it, or
- it is very low on the priorities of the person who is responsible for it, or
- the person responsible for it does not have the resources to do the work.
Therefore, step one in solving such a problem is to appoint someone who is responsible for it, and ensure they have the motivation and resources to do the work.
In metadata governance, we refer to the person responsible for ensuring that metadata about a service or dataset is complete, accurate and up-to-date as the owner. The owner may not personally maintain the metadata since this may be automated, or be handled by others. However, if there are problems with the metadata, the owner is the person responsible for sorting it out.
Fixing the bus timetables
The managing director considered the inaccurate bus timetable information as a serious problem that urgently needed fixing. She discovered that the manager responsible for scheduling the bus drivers' shifts was the one who made changes to the timetable. These changes typically occurred whenever there was a persistent difficulty in assigning a bus driver to a route. Whenever this happened, he briefed the affected driver with the change and asked that they disseminate the information to their passengers.
The bus drivers' manager was given ownership for ensuring the bus timetables were accurate at each bus stop since he was responsible for the action that triggered a need to update the timetables. He also understood the scope of any change.
The bus drivers' manager was given a new assistant. Part of the assistant's role was to make changes to the master timetables when necessary, arrange for the downloadable timetables to deliver the new version, get printed copies to the bus station and tourist information office and add an article to the local paper describing the change. They would also drive around to the affected bus stops and update the timetable as well as ensure the affected buses had new copies of the bus timetable onboard for their regular customers.
In the example above, the managing director identified where the action was occurring that should trigger the change. She assigned an owner and ensured they had the resources (ie the new assistant) to ensure the updates were done.
When a change to the timetable occurred, the bus drivers' manager triggered the assistant to update the master bus timetable. The updated timetable was then transformed into multiple formats and disseminated to all the places where their customers are likely to notice the change. Their challenge is to both create awareness that the change has happened and provide the updated information.
Metadata governance three-step process¶
We can generalise this process as follows, creating a reusable specification pattern for all forms of governance:

A three-step specification pattern of Trigger, Take Action and Make Visible.
For metadata governance, the Take Action is typically an update to metadata. For example, if a new deployment of a database occurs in the digital world, it could trigger a metadata update to capture any schema changes and then information about these changes is disseminated to the tools and consumers that need the information.
The dissemination of specific changes to metadata can also act as a trigger for other metadata updates. For example, the publishing of changes to a database schema could trigger a data profiling process against the database contents. The data profiling process adds new metadata elements to the existing metadata, and hence the knowledge graph of metadata grows.

The specification pattern above applies whether the governance is manual or automated. All that changes is the mechanism.
Triggers may be time-based, or an unsolicited update to metadata by an individual. For example, data profiling may be triggered once a week as well as whenever the schema changes. A comment attached to a database description that reports errors in the data may trigger a data correction initiative.
Consider metadata as a collection of linked facts making up a knowledge graph that describes the resources and their use by the organization. The role of the tools, people and open metadata technology is to build, maintain and consume this knowledge graph to improve the operation of the organization.
Enriching customer service
The managing director of the bus company picks up a changing perspective in the head office employees since the implementation of the bus timetable management process. Rather than a focus on running the buses, there is a growing understanding that they are providing a service to their customers.
Eager to build on this change, the managing director encourages her employees to bring forward ideas that increase their customer service. These ideas include disseminating information about local events (along with information about to get to the event by bus, of course :)).
As a result, the bus timetables began to include a calendar of local events. Event organizers were able to register their events with the bus company and negotiate for additional buses where necessary. New bus routes are identified and begin to operate. The effect is that the bus company became an active member of the community, with increasing bus use and associated profits.
When metadata governance is done well, a rich conversation develops between service providers and their consumers that can lead to both improvements in the quality of the services and the expansion in the variety and amount of consumption; the real value of the service is measured by consumption.
New uses for the services will then emerge ... growing the vitality and value to the organization.
The open metadata ecosystem (15 mins)
The open metadata ecosystem¶
The content of the data/metadata shared between teams needs to follow standards that ensure clarity, both in meaning and how it should be used and managed. Its completeness and quality need to be appropriate for the organization's uses. These uses will change over time.
The ecosystem that supplies and uses this data/metadata must evolve and adapt to the changing and growing needs of the organization because trust is required not just for today's operation but also into the future.
You can make your own choices on how to build trust in your data/metadata. Egeria provides standards, mechanisms and practices built from industry experiences and best practices that help in the maintenance of data/metadata:
-
Egeria defines a standard format for storing and distributing metadata. This includes an extendable type system so that any type of metadata that you need can be supported.
-
Egeria provides technology to manage, store, distribute this standardized metadata. This technology is inherently distributed, enabling you to work across multiple cloud platforms, data centres and other distributed environments. Collectively, a deployment of this technology is referred to as the open metadata ecosystem.
-
Egeria provides connector interfaces to allow third party technology to plug into the open metadata ecosystem. These connectors translate metadata from the third party technology's native format to the open metadata format. This allows:
- Collaboration
- Blending automation and manual processes
- Comprehensive security and privacy controls
-
Egeria's documentation provides guidance on how to use this technology to deliver business value.
In this dojo we will cover these mechanisms and practices, showing how they fit in the metadata update specification pattern described above. You can then select which are appropriate to your organization and when/where to consider using them.
Different categories of metadata (25 mins)
Categories of metadata¶
Metadata is often described as data about data. However, this definition does not fully convey the breadth and depth of information that is needed to govern your digital operations.
The categories of metadata listed below help you organize your metadata needs around specific triggers that drive your metadata ecosystem.
Technical metadata
Technical metadata¶
The most commonly collected metadata is technical metadata that describes the way something is implemented. For example, technical metadata for common digital resources includes:
- The databases and their database schema (table and column definitions) configured in a database server.
- APIs and their interface specification implemented by applications and other software services to request actions and query data.
- The events and their schemas used to send notifications between applications, services and servers to help synchronize their activity.
- The files stored on the file system.
Technical metadata is the easiest type of metadata to maintain since many technologies provide APIs/events to query the technical metadata for the digital resources it manages.
To keep your technical metadata up-to-date you need to consider the following types of metadata update triggers:
- whenever new digital resources are deployed into production,
- events that indicate that the digital resources have changed
- regular scanning of the deployed IT environment to validate that all technical metadata has been captured (and nothing rogue has been added).
Ideally you want your metadata governance to engage in the lifecycles that drive changes in the technical metadata - for example, adding management of technical metadata as part of the software development lifecycle (SDLC) or CI/CD pipelines.
Collecting and maintaining technical metadata builds an inventory of your digital resources that can be used to count each type of digital resources and act as a list to work through when regular maintenance is required. It also helps people locate specific types of digital resources.
Data content analysis results
Data content analysis results¶
The technical metadata typically describes the structure and configuration for digital resources. Analysis tools can add to this information by analysing the data content of the digital resources. The results create a characterization of the data content that helps potential consumers select the digital resources best suited for their needs.
Data content analysis is often triggered periodically, based on the update frequency that the digital resource typically experiences. It can also be triggered when the technical metadata is first catalogued or updated. If the digital resource is really important, and used in Analytics/AI you need to check more often to validate that no significant changes have occurred.
Consumer metadata
Consumer metadata¶
Consumer metadata includes the comments, reviews, tags added by the users that are consuming the metadata and the digital resources it describes. This metadata is gathered from the tools through which the users consume the metadata and the digital resources. It is then used to assess the value and popularity of the metadata and digital resources to the broader community.
Metadata update triggers should focus around the tools where the consumer feedback is captured. Typically, each piece of consumer feedback is treated as a separate trigger. The feedback should then be distributed to the tools that are used by the owning team. This could trigger changes to the resource. Ideally, the owning team should be able to respond and demonstrate they are listening and taking action.
Subject area materials
Subject area materials¶
Subject areas are topics or domains of knowledge that are important to the organization. Typically, they cover content that is widely shared across the organization and there is business value in maintaining consistency. The materials for a subject area typically includes:
- Glossary definitions describing the meaning of data values,
- Reference data describing valid values and mappings for data values,
- Technical controls defining quality rules and processing rules - such as anonymization/encryption requirements,
- Terms and conditions of use,
- Governed data classifications such as level of confidentiality, expected retention period, how critical this type of data is ...,
- Data classes are logical types for data used to characterize data during analysis.
- Standard/preferred schemas and associated implementation snippets to guide developers to improve the consistency of data representation across the digital landscape.
Assets that are managed using the subject area's materials are said to be part of the subject area's domain. This is called the Subject Area Domain and is synonymous with Data Domain - although a subject area domain may manage assets that are not data assets (such as systems and infrastructure) which is why open metadata uses a more generic name.
Updates to the subject area materials are typically made offline, collected, and then disseminated together as a new release. Therefore, the metadata update trigger is often related to the release of a collection of subject area materials.
Governance metadata
Governance metadata¶
Governance metadata describes the requirements of a particular Governance Domain and their associated controls, metrics and implementations. They are managed in releases in a similar way to subject area materials. Therefore, their releases act a triggers to further actions.
Organizational metadata
Organizational metadata¶
Organizational metadata describes the teams, people, roles, projects and communities in the organization. This metadata is used to coordinate the responsibilities and activities of the people in the organization. For example, roles can be defined for the owners of specific resources, and they can be linked to the profiles of the individuals appointed as owner. This information can be used to route requests and feedback to the right person.
Organization metadata is often managed in existing applications run by Human Resources and Corporate Security. Therefore, updates in these applications are used to trigger updates to the organizational metadata in the open metadata ecosystem.
Governance actions can trigger the creation of new roles and appointments to these roles. These elements can be then be disseminated to the appropriate applications for information, verification and/or approval.
Business context metadata
Business context metadata¶
An organization has capabilities, facilities and services. The digital resources it uses, serve these purposes. When decisions need to be made as to which digital resources to invest in, it is helpful to understand which part of the business will be impacted.
Information about the organization's capabilities, facilities and services is called business context. Often individuals core role is focuses on these aspects. Linking them to the digital resources that they depend on (often invisible to these individuals) helps to raise awareness of the mutual dependency and understanding of the impact/value of change at either level.
Triggers that detect change in digital resources (for example an outage) can result in information flowing to the appropriate business teams. If the change (or outage) is extensive, the linked business context can be used to prioritize the associated work.
Process metadata
Process metadata¶
Data is copied, combined and transformed by applications, services, processes and activities running in the digital landscape. Capturing the structure of this processing shows which components are accessing and changing the data. This Process Metadata is a key element in providing lineage, used for traceability, impact analysis and data observability.
The capture and maintenance of process metadata is typically triggered as process implementations are deployed into production.
Operational metadata
Operational metadata¶
Operational metadata describes the activity running in the digital landscape. For example, process metadata could describe the steps in an ETL job that copies data from one database to another. The operational metadata captures how often it runs, how many rows it processed and the errors it found.
Operational metadata is often captured in log files. As they are created, they trigger the cataloging and linking of their information into other types of metadata.
Metadata relationships and classifications¶
The other types of trigger to consider is when/where the metadata elements described above can be connected together and augmented.
This linking and augmentation of metadata has a multiplying effect on the value of your metadata.
You can think of the metadata described above as the facts about your organization's resources and operation. Metadata relationships that show how one element relates to another, begin to show the context in which decisions are made and these resources are used.
Metadata classifications are used to label metadata as having particular characteristics. This helps group together similar elements, or elements that represent resources that need similar processing
Summary
Hopefully the discussion above has helped to illustrate that metadata is varied and can be built into a rich knowledge base that drives organizational objectives through increased visibility, utilization and management of an organization's digital assets.
Open metadata types (25 mins)
The open metadata type system¶
Knowledge about data is spread amongst many people and systems. One of the roles of a metadata repository is to provide a place where this knowledge can be collected and correlated, as automated as possible. To enable different tools and processes to populate the metadata repository we need agreement on what data should be stored and in what format (structures).
Open metadata subject areas¶
The different subject areas of metadata that we need to support for a wide range of metadata management and governance tasks include:
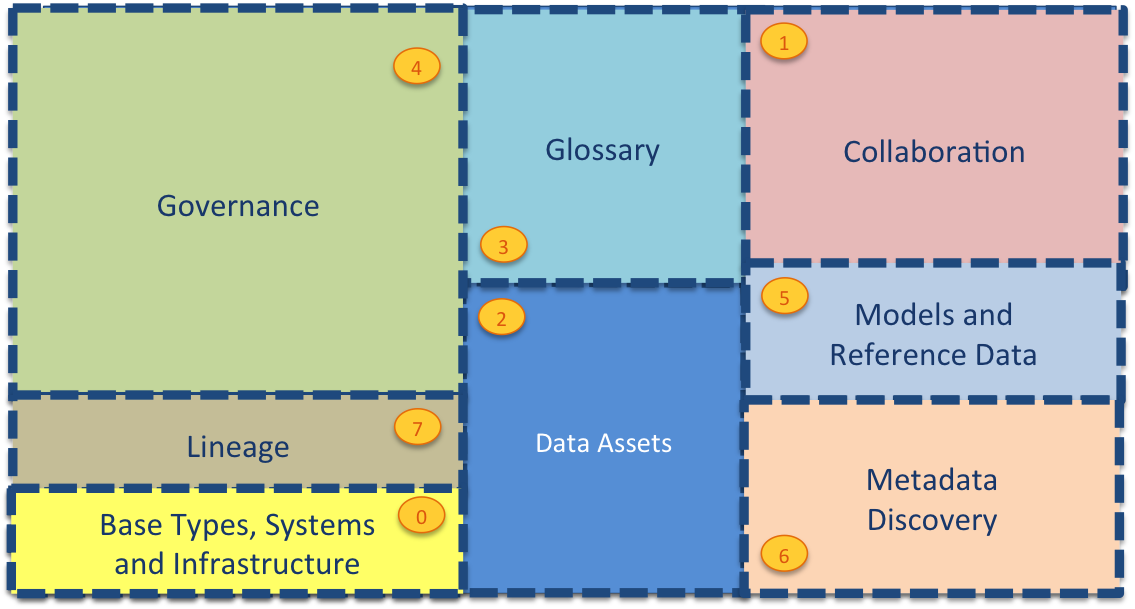
This metadata may be spread across different metadata repositories that each specialize in particular use cases or communities of users.
| Area | Description |
|---|---|
| Area 0 | describes base types and infrastructure. This includes the root type for all open metadata entities called OpenMetadataRoot and types for Asset, DataSet, Infrastructure, Process, Referenceable, SoftwareServer and Host. |
| Area 1 | collects information from people using the data assets. It includes their use of the assets and their feedback. It also manages crowd-sourced enhancements to the metadata from other areas before it is approved and incorporated into the governance program. |
| Area 2 | describes the data assets. These are the data sources, APIs, analytics models, transformation functions and rule implementations that store and manage data. The definitions in Area 2 include connectivity information that is used by the open connector framework (and other tools) to get access to the data assets. |
| Area 3 | describes the glossary. This is the definitions of terms and concepts and how they relate to one another. Linking the concepts/terms defined in the glossary to the data assets in Area 2 defines the meaning of the data that is managed by the data assets. This is a key relationship that helps people locate and understand the data assets they are working with. |
| Area 4 | defines how the data assets should be governed. This is where the classifications, policies and rules are defined. |
| Area 5 | is where standards are established. This includes data models, schema fragments and reference data that are used to assist developers and architects in using best practice data structures and valid values as they develop new capabilities around the data assets. |
| Area 6 | provides the additional information that automated metadata discovery engines have discovered about the data assets. This includes profile information, quality scores and suggested classifications. |
| Area 7 | provides the structures for recording lineage and providing traceability to the business. |
The following diagram provides more detail of the metadata structures in each area and how they link together:
Metadata is highly interconnected
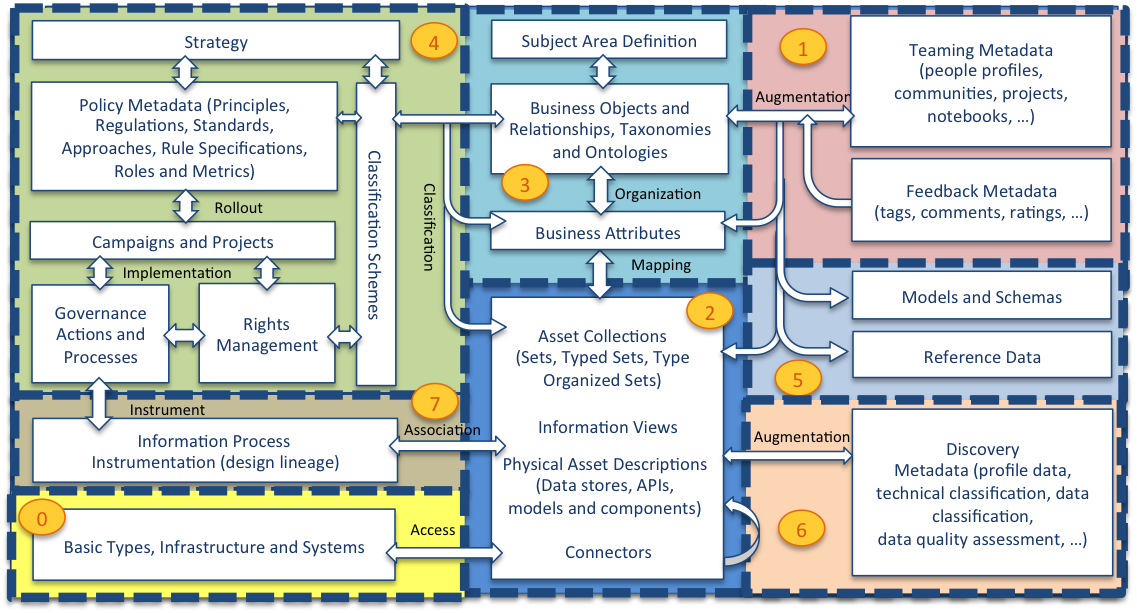
Bottom left is Area 0 - the foundation of the open metadata types along with the IT infrastructure that digital systems run on such as platforms, servers and network connections. Sitting on the foundation are the assets. The base definition for Asset is in Area 0 but Area 2 (middle bottom) builds out common types of assets that an organization uses. These assets are hosted and linked to the infrastructure described in Area 0. For example, a data set could be linked to the file system description to show where it is stored.
Area 5 (right middle) focuses on defining the structure of data and the standard sets of values (called reference data). The structure of data is described in schemas and these are linked to the assets that use them.
Many assets have technical names. Area 3 (top middle) captures business and real world terminologies and organizes them into glossaries. The individual terms described can be linked to the technical names and labels given to the assets and the data fields described in their schemas.
Area 6 (bottom right) captures additional metadata captured through automated analysis of data. These analysis results are linked to the assets that hold the data so that data professionals can evaluate the suitability of the data for different purposes. Area 7 (left middle) captures the lineage of assets from a business and technical perspective. Above that in Area 4 are the definitions that control the governance of all of the assets. Finally, Area 1 (top right) captures information about users (people, automated process) their organization, such as teams and projects, and feedback.
Within each area, the definitions are broken down into numbered packages to help identify groups of related elements. The numbering system relates to the area that the elements belong to. For example, area 1 has models 0100-0199, area 2 has models 0200-299, etc. Each area's sub-models are dispersed along its range, ensuring there is space to insert additional models in the future.
Test yourself ...
Fill in the following table to map the areas of the open metadata type system to the different categories of metadata.
| Open Metadata Area | Categories of metadata covered by this Area - choose from Technical metadata, Data content analysis results, Consumer metadata, Subject area materials, Governance metadata, Organizational metadata, Business context metadata, Process metadata and Operational metadata. |
|---|---|
| 0 - Base Types, Systems and Infrastructure | |
| 1 - Collaboration | |
| 2 - Data Assets | |
| 3 - Glossary | |
| 4 - Governance | |
| 5 - Models and Reference Data | |
| 6 - Metadata Discovery | |
| 7 - Lineage |
Answer
| Open Metadata Area | Categories of metadata covered by this Area |
|---|---|
| 0 - Base Types, Systems and Infrastructure | Technical Metadata |
| 1 - Collaboration | Consumer Metadata, Organizational Metadata |
| 2 - Data Assets | Technical Metadata |
| 3 - Glossary | Subject Area Materials |
| 4 - Governance | Subject Area Materials, Governance Metadata, Operational Metadata (associated assets) |
| 5 - Models and Reference Data | Technical Metadata, Subject Area Materials |
| 6 - Metadata Discovery | Data Content Analysis Results |
| 7 - Lineage | Business Context, Process Metadata |
Designing your metadata supply chains (45 mins)
Metadata supply chains¶
The open metadata ecosystem collects, links and disseminates metadata from many sources. However, it is designed in an iterative, agile manner, adding new use cases and capabilities over time.
Each stage of development considers a particular source of metadata and where it needs to be distributed to. Consider this scenario...
Database schema capture and distribution
There is a database server (Database Server 1) that is used to store application data that is of interest to other teams. An initiative is started to automatically capture the schemas of the databases on this database server. This schema information will be replicated to two destinations:
- Another database server (Database Server 2) is used by a data science team as a source of data for their work. An ETL job runs every day to refresh the data in this second database with data from the first database. The data is anonymized by the ETL job, but the schema and data profile remains consistent. If the schema in the first database changes, the ETL job is updated at the same time. However, the schema in the second database is not updated because the team making the change do not have access to it. Nevertheless it must be updated consistently before the ETL job runs; otherwise it will fail.
- The analytics tool that is also used by the data science team has a catalog of data sources to show the data science team what data is available. This needs to be kept consistent with the structure of the databases. The tool does provide a feature to refresh any data source schema in its catalog, but the team are often unaware of changes to their data sources, or simply forget to do it, and only discover the inconsistency when their models fail to run properly.

The integration of these third party technologies with the open metadata ecosystem can be thought of as having four parts to it.
- Any changes to the database schema are extracted from Database Server 1 and published to the open metadata ecosystem.
- The new schema information from Database Server 1 is detected in the open metadata ecosystem and deployed to Database Server 2.
- The changes to Database Server 2's schema are detected and published to the open metadata ecosystem.
- The new schema information from Database Server 2 is detected in the open metadata ecosystem and distributed to the Analytics Workbench.

Four integration steps to capture and distribute the database schema metadata from Database Server 1.
Here is another view of the process, but shown as a flow from left to right.

At each stage, there is a trigger (typically detecting something has changed), metadata is assembled, updated and when it is read, made visible through the open metadata ecosystem.

A three-step specification pattern of Trigger, Maintain Metadata and Make Visible.
The implementation of the three-step pattern for each part of the integration is located in an integration connector. Integration connectors are configurable components that are designed to work with a specific third party technology. There would be 4 configured integration connectors to support the scenario above. However, the implementation of the integration connectors for parts 1 and 3 would be the same implementation, just 2 instances, each configured to work with a different database server.
The integration connectors supplied with Egeria are described in the connector catalog. It is also possible to write your own integration connectors if the ones supplied by Egeria do not meet your needs.
Integration connectors run in the Integration Daemon. It is possible to have all 4 integration connectors running in the same integration daemon. Alternatively, they each may run in a different integration daemon - or any combination in between. The choice is determined by the organization of the teams that will operate the service. For example, if this metadata synchronization process was run by a centralized team, then all 4 integration connectors would probably run in the same integration daemon. If the work is decentralized, the integration connector for part 1 may be in an integration daemon operated by the same team that operates Database Server 1. The other integration connectors may run together in an integration daemon operated by the team that operates Database Server 2 and the Analytics Workbench.
The diagram below shows the decentralized option.

This type of deployment choice keeps control of the metadata integration with the teams that own the third party technology, and so upgrades, back-ups and outages can be coordinated.
The implementation of the open metadata ecosystem that connects the integration daemons can also be centralized or decentralized. This next diagram shows two integration daemons connecting into a centralized metadata access store that provides the open metadata repository.

Alternatively, each team could have their own metadata access store, giving them complete control over their metadata. The two metadata access stores are connected via an Open Metadata Repository Cohort (or just "cohort" for short.) The cohort enables the two metadata access stores to operate as one logical metadata store.

The behaviour of the integration daemons is unaffected by the deployment choice made for the metadata access stores.
Adding lineage¶
In the scenario above, data from Database Server 1 is extracted, anonymized and stored in Database Server 2 by an ETL job running in an ETL engine.

The data scientist team want to know the source of each of the databases they are working with. The metadata that describes the source of data is called lineage. Ideally it is captured by the ETL engine to ensure it is accurate.
ETL engines have a long history of capturing lineage, since it is a common requirement in regulated industries. The diagram below shows three choices on how an ETL engine may handle its lineage metadata.
- In the first box on the left, the ETL engine has its own metadata repository and so it is integrated into the open metadata ecosystems via the integration daemon (in the same way as the database and analytics workbench).
- In the middle box, the ETL engine is producing lineage events that follow the OpenLineage Standard. The integration daemon has native support for this standard and so the ETL Engine can send these events directly to the integration daemon which will pass them to any integration connector that is configured to receive them.
- The final box on the right-hand side shows an ETL engine that is part of a suite of tools that share a metadata repository. These types of third party metadata repositories often have a wide variety of metadata that is good for many use cases. So, although it is possible to integrate them through the integration connectors running in the integration daemon, it is also possible to connect them directly into the cohort via a Repository Proxy. This is a more complex integration to perform. However, it has the benefit that the metadata stored in the third party metadata repository is logically part of the open metadata ecosystem and available through any of the open metadata and governance APIs without needing to copy its metadata into a metadata access store.

Summary
In this guide you have seen that integration with the open metadata ecosystem is built up iteratively using integration connectors running in an integration daemon. Open metadata is stored in metadata access stores and shared across the open metadata ecosystem using a cohort. It is also possible to plug in a third party metadata repository using a repository proxy.

Automating metadata capture (30 mins)
Automating metadata capture¶
People are not good at repetitive admin tasks, particularly if these tasks are not the primary focus of their work. Therefore, the open metadata ecosystem is more complete and accurate when automation supports these mundane tasks. Following our three step model, the automation needs to:
- monitor for triggers that indicate that metadata needs to be updated,
- drive the necessary changes to metadata and then
- make those changes visible to downstream processing.
A three-step specification pattern of Trigger, Maintain Metadata and Make Visible.
Introducing the integration daemon
Inside the Integration Daemon¶
Recap: The Integration Daemon is an Egeria OMAG Server that sits at the edge of the open metadata ecosystem, synchronizing metadata with third party tools. It is connected to a Metadata Access Server that provides the APIs and events to interact with the open metadata ecosystem.

The integration can be:
-
Triggered by an event from a third party technology that indicates that metadata needs to be updated in the open metadata ecosystem to make it consistent with the third party technology's configuration.
-
Triggered at regular intervals so that the consistency of the open metadata ecosystem with the third party technology can be verified and, where necessary, corrected.
-
Triggered by a change in the open metadata ecosystem indicating that changes need to be replicated to the third party technology.
Running in the integration daemon are integration connectors that each support the API of a specific third party technology. The integration daemon starts and stops the integration connectors and provides them with access to the open metadata ecosystem APIs. Its action is controlled by configuration, so you can set it up to exchange metadata with a wide range of third party technologies.
An integration connector is specialized for a particular technology. The integration daemon provides specialized services focused on different types of technology, in order to simplify the work of the integration connector. These specialized services are called the Open Metadata Integration Services (OMISs). Each integration connector is paired with an OMIS and, the OMIS is paired with a relevant Open Metadata Access Service (OMAS) running in a Metadata Access Server.

Further information
Subject Areas (1.5 hours)
Subject Areas¶
Back at the bus company ...
The new focus on ensuring bus timetable information is accurate and available has created an increase in passengers for the bus company. The assistant who is responsible for managing and disseminating the bus timetable information is not happy, however. What should be a simple task is tedious and complicated because each form of the timetable (at the bus stop, internet download, printed timetables) are each using a different format. For example, the master timetable and the timetables for the bus stop are in 24-hour clock, whereas the internet downloadable timetable and the printed timetable use am/pm. This means the assistant has to translate the bus times from one format to another in order to publish a new set of timetables. Similarly, the names of the bus stops are not consistent across the different formats. The assistant realizes that some form of standardization is needed so that the different formats can be created automatically from the master timetables. Otherwise, they are going to look for a new job!
Using standard formats, names and meanings for resources, such as data, is critical to ensure they can be shared and reused for multiple purposes. Open metadata provides the means to describe these standards and used them to create consistency across all copies, formats and uses. The effort required to author and maintain a these standards, plus the governance processes required to ensure they are used wherever appropriate, is offset by the savings in managing and using the resources associated with the subject area.
Recap:
- Subject Areas define the standards for your resources and their use. They cover resources that are widely shared across the organization and there is business value in maintaining consistency.
- Each subject area has an owner who is responsible for coordinating the development and maintenance of the subject area's materials.
- Digital Resources that are managed using the subject area's materials are said to be part of the subject area's "domain". This is called the Subject Area Domain and is synonymous with Data Domain - although since a subject area domain may manage resources that are not just data assets (such as systems and infrastructure), open metadata uses a more generic name.
The glossary
The glossary is at the heart of the materials for a subject area. Figure 1 shows that the glossary contains glossary terms. Each glossary term describes a concept used by the business. It is also possible to link two glossary terms together with a relationship. The relationship may describe a semantic relationship or a structural one.

Figure 1: Glossaries for describing concepts and the relationships between them
Semantic relationships include:
- RelatedTerm is a relationship used to say that the linked glossary term may also be of interest. It is like a "see also" link in a dictionary.
- Synonym is a relationship between glossary terms that have the same, or a very similar meaning.
- Antonym is a relationship between glossary terms that have the opposite (or near opposite) meaning.
- PreferredTerm is a relationship that indicates that one term should be used in place of the other term linked by the relationship.
- ReplacementTerm is a relationship that indicates that one term must be used instead of the other. This is stronger version of the PreferredTerm.
- Translation is a relationship that defines that the linked terms represent the same meaning but each are written in a different language. Hence, one is a translation of the other. The language of each term is defined in the Glossary that owns the term.
- IsA is a relationship that defines that the one term is a more generic term than the other term. For example, this relationship would be used to say that "Cat" IsA "Animal".
Structural relationships in the glossary are relationships that show how terms are typically used together.
- UsedInContext links a term to another term that describes a context. This helps to distinguish between terms that have the same name but different meanings depending on the context.
- HasA is a term relationship between a term representing a SpineObject (see glossary term classifications below) and a term representing a SpineAttribute.
- IsATypeOf is a term relationship between two SpineObjects saying that one is the subtype (specialisation) of the other.
- TypedBy is a term relationship between a SpineAttribute and a SpineObject to say that the SpineAttribute is implemented using a type represented by the SpineObject
Further information
- See Area 3 in the Open Metadata Types to understand how these concepts are represented on open metadata.
Data classes
A data class provides the specification of a data type that is important to the subject area. Date, Social Security Number and Credit Card Number are examples of data classes.
The data class specification defines how to identify data fields of its type by inspecting the data values stored in them. The specification is independent of a particular technology, which is why they are often described as logical data types. The specification may include preferred implementation types for different technologies using Implementation Snippets.
Data classes are used during metadata discovery (see below) to identify the types of data in the discovered data fields. This is an important step in understanding the meaning and business value of the data fields. They can also be used in quality rules to validate that data values match the perscribed data class.
Data classes can be linked together in part-of and is-a hierarchies to create a logical type system for a subject area. A glossary term can be linked to a data class via an ImplementedBy relationship to identify the preferred data class to use when implementing a data field with meaning described in the glossary term. A data class can be linked to glossary term that describes the meaning of the data class via a SemanticAssignment relationship.

Figure 2: Data classes for describing the logical data types and implementation options
Further information
- See Model 0540 in the Open Metadata Types to understand how data classes are represented on open metadata.
- See Model 0737 in the Open Metadata Types to understand the ImplementedBy relationship.
- See Model 0370 in the Open Metadata Types to understand the SemanticAssignment relationship.
- See Model 0504 in the Open Metadata Types to understand ImplementationSnippets.
Consuming the glossary in design models
Design models (such as Concept models, E-R Models, UML models) and ontologies capture similar concepts to those described in the glossary. It helps if their definitions are consistent. When a new glossary is being built, existing models and ontologies can be used to seed the glossary. The models/ontologies themselves can be loaded in open metadata and the model elements linked to their corresponding glossary terms. Then new versions of the data models/ontologies can be generated from open metadata.

Figure 3: Linking to models
Any linked data classes provide details of language types to use when generating compliant artifacts from the models.
Further information
- See Model 0571 in the Open Metadata Types to understand how concept models are represented on open metadata.
- See Model 0565 in the Open Metadata Types to understand how design models are represented on open metadata.
Schemas
Schemas document the structure of data, whether it is stored or moving through APIs, events and data feeds. A schema is made up of a linked subgraph of schema elements. A schema begins with a schema element called a schema type. This may be a single primitive field, a set of values, an array of values, a map between two sets of values or a nested structure. The nested structure is the most common. In this case the schema type has a list of schema attributes (another type of schema element) that describe the fields in the structure. Each of these schema attributes has its own schema type located in its TypeEmbeddedAttribute classification.
Figure 4 shows a simple schema structure.

Figure 4: Schemas for documenting the structure of data
Further information
- See Schemas to understand how different types of schema are represented.
- See Model 0501 in the Open Metadata Types to see the formal definition of the different types of schema elements.
- See Model 0505 in the Open Metadata Types to understand schema attributes and the TypeEmbeddedAttribute classification.
Schemas and assets
An asset describes a valuable digital resource. Such resources include databases, data files, documents, APIs, data feeds, and applications. A digital resource can be dependent on other digital resource to fulfill their implementation. This relationship is also captured in open metadata with relationships such as DataSetContent. These relationships help to highlight inconsistencies in the assets' linkage to the subject area's materials, which may be due to errors in either the metadata or the implementation/deployment/use of the associated digital resources.

Figure 5: Dependencies between digital resources are reflected in open metadata by relationships between assets
Since schema types describe the structure of data, they can be attached to assets using the AssetSchemaType relationship to indicate that this asset's data is organized as described by the schema. Schemas are important because they show how individual data values are organized. Governance is often concerned with the meaning, correctness and use of individual data values since they are used to influence the decisions made within the organization. Therefore, even though the content of a schema bulks up the size and complexity of the metadata, it is necessary to capture this detail.

Figure 6: Schemas describe the structure of the data store in a digital resource (described by the asset in the catalog)
A schema is typically attached to only one asset since it is classified and linked to other elements assuming that the asset/schema combinations describes the particular collection of data stored in the associated digital resource. However, there is still a role for the subject area materials to provide preferred schema structures for software developers, data engineers and data scientists to use when they create implementations of new digital resources.
When a new asset is created, the schema definition in the subject area can be used as a template to define the schema for the asset (see figure 7). Then:
- The digital resource can be generated from the asset/schema, or
- Metadata discovery (see below) can be used to validate that the schema defined in the digital resource matches the schema associated with the asset.

Figure 7: Using a schema from a subject are as a template for a new asset
There is also an opportunity to share schemas between assets using an ExternalSchemaType. This option has the advantage that there only one copy of the schema. However, it is only used when all classifications and relationships attached to the shared part of the schema apply to all data in the associated digital resources.

Figure 8: Using an external schema type to share a common schema
Further information
- See Model 0503 in the Open Metadata Types to understand the AssetSchemaType relationship.
- See Model 0501 in the Open Metadata Types to understand how schemas are represented on open metadata.
- See Model 0505 in the Open Metadata Types to understand how schema attributes are represented on open metadata.
Reference value assignments
The materials for a subject area may include sets of values used to label metadata elements to show that they are in a particular state or have a specific characteristic that is important in the subject area. For example, a subject area about people may include the notion of an Adult and a Child (or Minor). The age of majority is different in each country and so a simple label assigned to a Person profile that indicates that a person is an adult would allow the knowledge of how to determine if someone is an adult to be contained around the maintenance of the person profiles, while the reference data value is used in multiple places.
These labels are called reference data values and are managed in Valid Value Sets. The association between a reference data value and a metadata element is ReferenceValueAssignment.

Figure 9: Labelling using reference data values
Further information
- Reference Data Management describes different uses of valid value sets.
Schema assignments
Figure 10 show three types of assignments between the metadata associated with a digital resource (technical metadata) and the subject area materials:
- SemanticAssignment - Semantic assignments indicate that the data stored in the associated data field has the meaning described in the glossary term.
- ValidValuesAssignment - Valid value sets define a list of valid values. They can be used to the values that are allowed to be stored in a particular data field if it can be described as a discrete set.
- DataClassAssignment - A data class assignment means that the data in the data field conforms to the type described in the data class.
When these relationships are used in combination, there should be consistency between the assignments to the data field and those to the associated glossary term.

Figure 10: Using assignment relationships to create a rich description of the data stored in a schema attribute (data field)
Governed data classifications
Governed data classifications can be attached to most types of metadata elements. They can also be assigned to glossary terms to indicate that the classification applies to all data values associated with the glossary term. The governed data classifications have attributes that identify a particular level that applies to the attached element. The definition for each level can be linked to appropriate Governance Definitions that define how digital resources classified at that level should be governed. Governance Classification Levels are linked to Governance Definitions using the GovernedBy relationship.

Figure 11: Classifying glossary terms to identify the governance definitions that apply to all data values associated with the glossary term
Further information
- Setting up your Governance Program describes how different types of governance metadata are used.
Connectors and connections
The digital resources associated with the assets in the catalog are accessed through connectors. A Connector is a client library that applications use to access the data/function held by the digital resource. Typically, there is a specialized connector for each type of Asset/technology.
Sometimes there are multiple connectors to access a specific type of asset, each offering a different interface for the application to use.
Instances of connectors are created using the Connector Broker. The connector broker creates the connector instance using the information stored in a Connection. These can be created by the application or retrieved from the open metadata stores.
A connection is stored in the open metadata stores and linked to the appropriate asset for the digital resource.

Figure 12: Connection information needed to access the data held by an asset
Further information
- See the connector catalog to understand how connectors are used in Egeria.
- See Model 0201 in the Open Metadata Types to understand how connections are represented.
Metadata discovery
An open discovery service is a process that runs a pipeline of analytics to describe the data content of a resource. It uses statistical analysis, reference data and other techniques to determine the data class and range of values stored, potentially what the data means and its level of quality. The result of the analysis is stored in metadata objects called annotations.
Part of the discovery process is called Schema Extraction. This is where the discovery service inspects the schema in the digital resource and builds a matching structure of [DataField]/types/6/0615-Schema-Extraction/) elements in open metadata. As it goes on to analyse the content of a particular data field in the resource, it can add its results to an annotation that is attached to the DataField element. It can also maintain a link between the DataField element and its corresponding SchemaAttribute element if the schema has already been attached. Through ths process it is possible to detect any anomalies between the documented schema and what is actually implemented.
Part of the analysis of a single data field may be to identify its data class (or a list of possible data classes if the analysis is not conclusive). THe data class in turn may identify a list of possible glossary terms that could apply to the data field.
For example, there may be a data class called address. A discovery service may detect that an address is stored in a digital resource. The data class may be linked to glossary terms for Home Address, Work Location, Delivery Address, ... The discovery service may not be able to determine which glossary term is appropriate in order to establish the SemanticAssignment relationship, but providing a steward with a short list is a considerable saving.

Figure 13: Output from a metadata discovery service
Further information
- See Discovery and Stewardship to understand how metadata discovery works.
- See Area 6 in the Open Metadata Types to understand how discovery metadata is represented.
Bringing it all together
Figure 13 summarizes how the subject area materials create a rich picture around the resources used by your organization. As they link to the technical metadata, they complement and reinforce the understanding of your data. In a real-world deployment, the aim is to automate as much of this linkage as possible. This is made considerably easier if the implementation landscape is reasonable consistent. However, where the stored data values do not match the expected types defined in the schema, the metadata model reveals the inconsistencies and often requires human intervention to ensure the links are correct.

Figure 14: Linking the metadata together
Defining subject areas in Egeria
- Governance Program OMAS provided support for the definition of subject areas and the ability to retrieve details of the materials that are part of the subject area.
- Digital Architecture OMAS supports the definition of valid value sets and quality rules for the subject area.
- Asset Manager OMAS supports the management of glossaries and the exchange of subject area materials with other catalogs and quality tools.
-
The Defining Subject Areas scenario for Coco Pharmaceuticals walks through the process of setting up. There are two code samples associated with this set of subject areas:
- Setting up the subject area definitions
- Setting up glossary categories for each subject area ready for subject area owners to start defining glossary terms associated with their subject area.
Coco Pharmaceuticals Scenarios
There are descriptions of creating glossaries and other materials for subject areas in the Coco Pharmaceuticals Scenarios.
Using automated governance actions (3.5 hours)
Using automated governance actions¶
The open metadata ecosystem collects, links and disseminates metadata from many sources. Inevitably there will be inconsistencies and errors in the metadata and there need to be mechanism that help identify errors and control how they are corrected. This section focuses on the automated processes that validate, correct and enrich the metadata in the open metadata ecosystem.
The shearing layers of governance actions (1 hour)
The building industry has the principle of shearing layers in the design of a building. This principle is as follows:
... Things that need to change frequently should be easy to change. Those aspects that change infrequently can take more effort and time.
In Egeria, the shearing layer principle is evident in the design of automated governance. An organization that is maturing their governance capability needs to be able to move fast. These automations need to be quick to create and quick to change. There is no time to wait for a software developer to code each one.
Egeria defines flexible components called governance services that can be re-configured and reused in many situations. Collectively the governance services form a pallet of configurable governance functions. The governance team link them together into a new process every time they need a new governance automation.
The advantage of this approach is the ability to rapidly scale out your governance capability. The downside is that there are more moving parts and concepts to understand.
The diagram below summarizes how Egeria's governance automation works. Descriptions of each layer follows the diagram.

At the base are the governance service components
Governance services are coded in java and packaged in Java Archives (Jar files). They need to be passed information about the function to perform and the metadata elements on which to operate since this will different each time they are called.
Part of the implementation is a connector provider that is able to return a description of its governance service in the form of a connector type. The connector type provides information about how to configure and run the governance service. This includes:
- A description of the connector's function
- Names of configuration properties that can modify the behaviour of the governance service.
- A list of request types that select which function it is to perform.
-
Names of request parameters that can be supplied (typically by the caller) that can override the configuration properties and/or provide the identifier(s) of any metadata element(s) to work on.
-
Names of supported action targets that provide links to the metadata element(s) to work on. The action target mechanism is typically used when governance services are being called in a sequence from a governance action process. The action targets are used to pass details of the metadata elements to work on from service to service.
The governance service definitions
The JAR file is added to the CLASSPATH of Egeria's platform where is can be loaded and inspected. The architect extracts the connector type of the governance service implementation and creates at least one governance service definition for it. The governance service definition is metadata that includes a GovernanceService entity, a Connection entity and a ConnectorType entity (based on the connector type extracted from the implementation) linked together. The connection entity will include the settings for the various configuration properties described in the connector type. If different combinations of configuration properties are desired, they are configured in different governance service definitions.
The governance engine definitions
The architect then builds a governance engine definition. This is metadata that defines a list of governance request types. These are the names of the functions needed by the governance team.
Each governance request type is mapped to a governance service definition (defined above). The governance engine definition can include a mapping from the governance request type to a request type understood by the governance service implementation (called the serviceRequestType). Without this mapping, the governance request type is passed directly to the governance service implementation when it is called.
Typically, the governance engine definition is packaged in a open metadata archive called a governance engine pack. This can be loaded into any platform that is going to run the governance engine/services.

Engine actions
The governance engine is configured in an Engine Host server running on the platform. The governance engine can be called by creating an engine action. This is a metadata entity that describes the governance request type and request parameters to run on a specific governance engine. The engine action content is broadcast to all the running engine hosts via the Governance engine OMAS Out Topic. On receiving this event, each engine host consults their active governance engines to see if the governance request type is supported. The first engine host to detect the new engine action will claim the engine action, which changes it status from WAITING to ACTIVATING in the open metadata ecosystem. The successful Engine Host then passes the request to its governance engine to execute and the engine action's status moves to IN_PROGRESS. The results of the execution are also stored in the engine action including the final status (ACTIONED, INVALID or FAILED).
Governance services produce one or more guards when they complete. Guards describe the outcome of running the governance service. They are stored in the governance action entity that kicked off the governance service. The governance action entities provide an audit trail of the automated governance actions that were requested, and their outcome.

Governance action processes
Governance action processes are defined in metadata using a set of linked governance action process steps. They are choreographed in a Metadata Access Server running the Governance Server OMAS. When the process is called to run, the Governance Server OMAS navigates to the first governance action process step in the governance action process flow. It creates a matching engine action entity. This is picked up by the engine host and executed in the governance engine just as if it was called independently. The guards are returned by the engine action as it completes. This change is detected by Governance Server OMAS which uses the guards to navigate to the next engine action process step(s) found in the governance action process flow. A engine action is created for each of the next governance action process steps and the cycle is repeated until there are no more governance action process steps in the governance action process flow to execute.
A governance action process can be run many times with different parameters. It can be changed, simply by updating the governance action process step metadata entities in the governance action process definition. New processes can be created by creating the appropriate governance process definition.
If a desired request type can not be supported by the existing governance services, a developer is asked to extend a governance service implementation or create a new one that can be configured into a governance engine to support the desired governance request type.
Governance services supplied with Egeria
Designing your governance processes (30 mins)
A governance action process is a predefined sequence of engine actions that are coordinated by the Governance Server OMAS.
The steps in a governance action process are defined by linked governance action process steps stored in the open metadata ecosystem. Each governance action process step provides the specification of the governance action to run. The links between them show which guards cause the next step to be chosen and hence, the governance action to run.
The governance action process support enables governance professionals to assemble and monitor governance processes without needing to be a Java programmer.
Examples¶
In the two examples below, each of the rounded boxes represent a governance action and the links between them is a possible flow - where the label on the link is the guard that must be provided by the predecessor if the linked governance action is to run.
The governance actions in example 1 are all implemented using governance action services. When these services complete, they supply a completion status. If a service completed successfully, they optionally supply one or more guards and a list of action targets for the subsequent governance action(s) to process.
The first governance action in example 1 is called when a new asset is created. For example the Generic Element Watchdog Governance Action Service could be configured to monitor for new/refresh events for particular types of assets and initiate this governance process then this type of event occurs.
The first governance action to run is Validate Asset. It retrieves the asset and tests that it has the expected classifications assigned. The guards it produces control with actions follow.
Governance actions from the same governance action processes can run in parallel if the predecessor governance actions produces multiple guards.

Example 1: Governance Action Process to validate and augment a newly created asset
Governance action processes can include any type of governance service. Example 2 shows an survey action service amongst the governance action services.

Example 2: Governance Action Process to validate and augment a newly created asset
Capturing lineage for a governance action process¶
The engine actions generated when a governance action process runs provide a complete audit trace of the governance services that ran and their results. The Governance Action Open Lineage Integration Connector is able to monitor the operation of the governance actions and produce OpenLineage events to provide operational lineage for governance action processes. Egeria is also able to capture these events (along with OpenLineage events from other technologies) for later analysis.
Governance Action Process Lifecycle¶
The diagram below shows a governance action process assembly tool taking in information from a governance engine pack to build a governance action process flow. This is shared with the open metadata ecosystem either through direct called to the Governance Server OMAS or via a open metadata archive (possibly the archive that holds the governance engine definition.
Once the definition of the governance action process is available, an instance of the process can be started, either by a watchdog governance action service or through a direct call to the Governance Server OMAS. Whichever mechanism is used, it results in the Governance Server OMAS using the definition to choreograph the creation of engine action entities that drive the execution of the governance services in the Engine Host.

Further information
- The 0462 Governance Action Processes model shows how the governance action process flow is built out of governance action process steps.
- Governance action processes may be created using the Governance Server OMAS API.
- The Open Metadata Engine Services (OMES) provide the mechanisms that support the different types of governance engines. These engines run the governance services that execute the engine actions defined by the governance action process.
Setting up an engine host, governance engines and services (30 mins)
Setting up the governance engine¶
Recap: A governance engine runs in an Engine Host on an OMAG Server Platform.
Like all types of OMAG Servers, the Engine Host is configured through Egeria's Administration Service and the result is a configuration document for the server.
The configuration document is loaded when the Engine Host is started. It contains a list of the governance engines that it are to run in the Engine Host. The configuration document also identifies the metadata access server that Engine Host is paired with, and where the name Governance Engine Definitions will be retrieved from.
For each governance engine name listed in the configuration document, the Engine Host calls its metadata access server to retrieve its Governance Engine Definition. Based on the contents of the Governance Engine Definition, the Engine Host starts up the appropriate Open Metadata Engine Services (OMESs) that hold the logic to run the different types of Governance Services defined in the Governance Engine Definition.

The Governance Engine Definition does not need to be loaded directly into the metadata access server paired with the Engine Host. It just needs to be in one of the Metadata Access Stores connected to the same cohort. A federated query is used to retrieve the Governance Engine Definition. This searches in across all the connected Metadata Access Stores. In fact, different parts of the Governance Engine Definition could be in different Metadata Access Stores. The team that build the Governance Services may publish their Governance Service Definitions to their local metadata store. An architect team responsible for building the Governance Engine Definition may have their own Metadata Access Store that holds the GovernanceEngine entity and the relationships to the GovernanceService entities in the Governance Services team's Metadata Access Store. As long as they are all connected by a cohort, they can all operate as if the whole Governance Engine Definition was in a single Metadata Access Store.

Recap: calls to a governance engine are made by initiating an Engine Action. This can be directly through an API call to the Governance Server OMAS running in a Metadata Access Store, or via a Governance Action Process.
A Governance Action is an entity in open metadata. When it is created in the Metadata Access Store, it sends an event to all connected Engine Hosts. If it is for a governance request type that one of its governance engine's supports, it claims the Governance Action and passes the request to its governance engine to run.
The nature of Egeria's open metadata ecosystem means that a Governance Action can be created in the paired Metadata Access Store ...

... or in a connected Metadata Access Store. Therefore, the Governance Services are available to any member of the open metadata ecosystem. They do not need to know where the Engine Hosts are deployed.

Further information
Using metadata discovery (1 hour)
Metadata discovery and stewardship¶
Metadata discovery is an automated process that extracts metadata about a digital resource. This metadata may be:
- embedded within the asset (for example a digital photograph has embedded metadata), or
- managed by the platform that is hosting the asset (for example, a relational database platform maintains schema information about the data store in its databases), or
- determined by analysing the content of the asset (for example a quality tool may analyse the data content to determine the types and range of values it contains and, maybe from that analysis, determine a quality score for the data).
Some metadata discovery may occur when the digital resource is first catalogued as an asset. Integrated cataloguing typically automates the creation the basic asset entry, its connection and optionally, its schema. This is sometimes called technical metadata.
Cataloguing database with integrated cataloguing
For example, the schema of a database may be catalogued through the Data Manager OMAS API. This schema may have been automatically extracted by an integration connector hosted in Egeria's Database Integrator OMIS.
The survey action services build on this initial cataloguing. They use advanced analysis to inspect the content of a digital resource to derive new insights that can augment or validate their catalog entry.
The results of this analysis is added to a survey report linked off of the asset for the digital resource.
The analysis results documented in the survey report report can either be automatically applied to the asset's catalog entry or it can go through a stewardship process where a subject-matter expert confirms the findings (or not).
Discovery and stewardship are the most advanced form of automation for asset cataloging. Egeria provides the server runtime environment and component framework to allow third parties to create survey action services and governance action implementations. It has only simple implementations of these components, mostly for demonstration purposes. This is an area where vendors and other open source projects are expected to provide additional value.
Survey action services¶
An survey action service is a component that performs analysis of the contents of a digital resource on request. The aim of the survey action service is to enable a detailed picture of the properties of a resource to be built up.
Each time a survey action service runs, it creates a new survey report linked off of the digital resource's Asset metadata element that records the results of the analysis.

Each time an survey action service runs to analyse a digital resource, a new survey report is created and attached to the resource's asset. If the survey action service is run regularly, it is possible to track how the contents are changing over time.
The survey report contains one or more sets of related properties that the survey action service has discovered about the resource, its metadata, structure and/or content. These are stored in a set of annotations linked off of the survey report.
An survey action service is designed to run at regular intervals to gather a detailed perspective on the contents of the digital resource and how they are changing over time. Each time it runs, it is given access to the results of previously run survey-action services, along with a review of these findings made by individuals responsible for the digital resource (such as stewards, owners, custodians).
Operation of an survey action service

- Each time a survey action service runs, Egeria creates a survey report to describe the status and results of the survey action service's execution. The survey action service is passed a survey context that provides access to metadata.
- The survey context is able to supply metadata about the asset and create a connector to the digital resource using the connection information linked to the asset. The survey action service uses the connector to access the digital resource's contents in order to perform the analysis.
- The survey action service creates annotations to record the results of its analysis. It adds them to the survey context which stores them in open metadata attached to the survey report.
- The annotations can be reviewed and commented on through an external stewardship process. This means choices from, for example, a list of potential options proposed by the survey action services, can be verified and the best one selected by an individual expert. The resulting choices are added to annotation reviews attached to the appropriate annotations.
- The next time the survey action service runs, a new survey report is created to link new attachments.
- The survey context provides access to the existing attachments for that asset along with any annotation reviews. The survey action services is able to link its new annotations to the existing annotations as an annotation extension. This means that the stewards can see the history associated with the new information.
Runtime for an survey action service
Survey action services are packaged into Survey Action Engines that run in the Survey Action OMES hosted in an Engine Host.
The metadata repository interface for metadata discovery tools is implemented by the Asset Owner OMAS that runs in a Metadata Access Server.
A survey action service may be triggered via an Engine Action, a governance action type or as part of a governance action process.

Inside the survey report¶
The survey report structures the annotations in two ways:
- Annotations that describe a characteristic of the whole digital resource.
- Annotations that describe a characteristic of a single data field within the digital resource.
The annotations for the data fields are linked off of the schema attributes created by schema extraction.

Survey actions¶
Survey actions can be used for the following types of analysis.
Schema extraction¶
For digital resources that include structured data, schema extraction documents the data fields present in the digital resource and if the schema is attached to the asset, it will attempt to match the data fields it finds to its schema attributes.
Schema extraction uses the schema analysis annotation. It is linked directly off of the survey report. The schema of the data in the digital resource is defined in a SchemaType linked from the digital resource's asset using the AssetSchemaType relationship. This may be established before the survey action service runs, or may be derived by the survey action service itself.
Resource profiling¶
Profiling analysis looks at the data values in the resource and summarizes their characteristics. There are three types of annotations used in resource profiling.
- Resource Profile Annotation - Capture the characteristics of the data values stored in a specific resource.
- Resource Profile Log Annotation - Capture the named of the log files where profile characteristics are captured. This is used when the profile results are too large to store in open metadata.
- Fingerprint Annotation - Capture the characteristics of the resource and express it as a single value.

For structured data, resource profiling needs to run after schema extraction to allow the resource profiling annotations that refer to a specific data field to be linked from the appropriate data field entity.
Data class discovery¶
Data class discovery captures the analysis on how close a data field matches the specification defined in a data class.

The recommendation for a specific data class are stored in a data class annotation linked off of the appropriate data field. Data class discovery needs to run after schema extraction. It often builds on the information provided by resource profiling.
Subsequent stewardship - either automated or with human assistance - can confirm the correct assignment using the DataClassAssignment relationship.
Semantic discovery¶
Semantic discovery is attempting to define the meaning of the data values in the asset. The result is a recommended glossary term stored as a semantic annotation.

These annotations are the metadata discovery equivalent of the Informal Tag shown in 0150 - Feedback in Area 1. It typically takes confirmation by a subject-matter expert to convert this into a Semantic Assignment. Semantic discovery needs to run after schema extraction. It often builds on the information provided by data profiling and data class discovery.
Classification discovery¶
Classification discovery adds recommendations for new classifications that should either be added to the asset, or to a schema attribute in the asset. It uses the classification annotation to describe the classification and its properties. If the classification is for the asset, the classification annotation is linked off of the discovery analysis report. If it is for a specific schema attribute, it is linked off of the corresponding data field.

Calculating quality scores¶
Quality scores describe how well the data values, typically in a data field, conform to a specification. For example, do the values match a list of valid values. This type of annotation is often used within a data quality program to provide assessments of the data for different purposes.

Relationship discovery¶
Relationship discovery identifies relationships between different resources (or data fields), such as two columns that have a foreign key relationship.
It is possible to create the relationship as a relationship annotation or attach a relationship advice to the discovery analysis report.

Capturing measurements¶
The measure annotations capture a snapshot of the physical dimensions and activity levels at a particular moment in time. For example, it may calculate the size of the resource or the number of users accessing it.

Requesting stewardship action¶
A RequestForAction entity (RfA) is used when a survey action service performs a test on the data (such as a quality rule) or has discovered an anomaly in the data landscape compared to its metadata that potentially needs a steward or a curator's action.

The Stewardship Action OMAS is designed to respond to the requests for actions (RfAs).
Working with external engines¶
Survey action services may directly implement the analysis function or may invoke an external service to create the annotations.
Initiating stewardship¶
Stewardship is initiated either through the creation of a Request for Action annotation or when the discovery analysis report's status changes to COMPLETE.
Further information
Raise an issue or comment below
Incident reporting and management (30 mins)
Incident Reporting¶
When errors, unexpected situations or special requests occur, it is not always obvious how they should be handled. An incident report is a metadata entity that describes a situation that needs special attention. It provides a focus point to coordinate efforts to resolve the situation.
The incident report is created when the situation is detected. The originator and known affected resources are linked to it.
As the incident is handled, details of the cause, additional affected resources, related incident reports and actions taken are attached to the incident report to create a complete record of the incident for future analysis.
There is a status in the incident report that records the progress to resolving the situation:
- Raised
- Reviewed
- Validated
- Resolved
- Invalid
- Ignored
- Other
The people working on the incident can add notes to the incident report's note log to communicate the diagnosis, steps taken and decisions made.

Overview of the Incident Management process
- When an incident occurs, an incident report is created. There is support to create an incident on most Open Metadata Access Services (OMASs), Open Metadata Integration Services (OMISs) supporting integration connectors and the Open Metadata Engine Services (OMESs) supporting governance services.
- the request is routed to Metadata Access Store and an IncidentReport entity linked to metadata describing the originator and any impacted resources is saved to its open metadata repository.
- The content of incident report is managed via the Stewardship Action OMAS's interface. This could be through direct calls to the API or via an integration connector running in the Stewardship Integrator OMIS

An Incident Management Example
In this example, there is a governance service called LDAP Verifier Governance Action Service that is running in an Engine Host. It is responsible for detecting whether there are any unexpected entries in Coco Pharmaceuticals' LDAP server that support access control.
It detects an unexpected member in the founders security group for a userId called matt-darker. Is this a valid entry and Egeria's list of user identities is out of date, or is this part of a cyber-attack? The governance action service creates an incident report identifying the security group and the unexpected userId.
The creation of the incident report in the open metadata ecosystem causes an event to be published by the Stewardship Action OMAS. It is picked up by an integration connector called Incident Manager Integration Connector. This integration connector publishes the incident report to Coco Phamaceuticals' security incident management system as an issue, where it is picked up by the security team to work on. Any relevant updates made to the issue in the security incident management system are detected by Incident Manager Integration Connector and reflected back in the incident report in the open metadata ecosystem.

Raise an issue or comment below
Examples of using automated governance
Working with governance metadata (1.5 hours)
Governance Zoning (30 mins)
Governance Zoning¶
A Governance Zone defines a list of elements, such as assets or digital products that are grouped together for a specific purpose. It may represent elements that are consumed or managed in a particular way; or should only be visible to particular groups of users, or processed by particular types of engine. There may also be zones used to indicate that the element is in a particular state.

Figure 1: Examples of types of zones
For example, Coco Pharmaceuticals use a quarantine zone for data that has arrived from an external partner. It is not visible to the researchers until it has been cataloged and verified. Then it is added to the zones that others can see.

Figure 2: Visibility rules associated with governance zones
Zones are typically independent of one another, but they can be nested if desired.
Defining governance zones¶
Governance zones are defined as part of the governance program. They are stored in open metadata as
GovernanceZone entities. They can be linked to governance definitions that may directly or indirectly identify the visibility rules that apply to the zone.

Figure 3: Visibility rules associated with governance zones
The visibility rules associated with the zones are typically executed via the server security connector that can both dynamically assign/augment the zones for an element before its security is checked and then use the setting of the element's zones to determine if the requested action by the requested user is allowed. The security connector may also delegate this decision to an external security manager where the zone information is typically transforming into security tags or settings in access control lists (ACLs).
Use cases¶
Governance zones help to support the following types of use cases:
- Data sovereignty - by defining zones that represent the origin of data and using visibility rules that match consumer to origin.
- Adjustments for legal jurisdiction - by defining zones for each jurisdiction and attaching appropriate rules to each.
- Asset visibility and access control - by defining zones that group elements into
- Data access control - using the zones assigned to the element when setting up security tags.
- Maintenance and backup processing - by defining zones that represent different archiving or maintenance requirements. The engines that perform the automated maintenance work through the list of elements in the relevant zones.
- Understanding dependencies between different parts of the organizations to support the information supply chains - by defining zones for different parts of the organization and visualizing
- Metering and billing - by defining zones that represent the cost structure of assets and using the zone membership of assets being used to determine the charge.
Membership of a zone¶
An element can belong to all, one or many zones. By default, it belongs to all zones. The ZoneMembership classification is used to restrict its visibility by specifying the list of zones that it belongs to in the zoneMembership property. If zoneMembership is null or empty, the element belongs to all zones, as if the element has no ZoneMembership classification. Otherwise, it belongs only to the zones that are listed. It is added to or removed from a zone by updating the ZoneMembership classification.
For example, as new data sets are onboarded, the setting of the templates or governance action services can ensure that the assets that represent these data sets are assigned to the right set of zones as they are added to the catalog. The zones can then be maintained as needed throughout the lifetime of the assets. If the assets become part of a digital product, their zone membership may be updated to match the zones for the overall digital product.

Figure : Examples of types of zones
When designing the governance zones for your organization, it is necessary to take care that the visibility rules associated with an element's zones are complementary rather than conflicting.
Here is an example:

Figure 5: Thinking through the meaning of belonging to multiple zones
Default zone settings¶
A Metadata Access Store can be configured with a list of zones to be assigned to new elements of a particular type. If the type for a new element is not featured in the default zones configuration then no zones are assigned to the element.
The default zones can be used to limit the number of users that can retrieve an element when it is first created. Once it is completely set up and approved, the ones can be updated to widen its visibility. One way to do this is using the publish zones.
Publish zone settings¶
A Metadata Access Store can also be configured with a list of zones to be assigned to elements of particular types when they are published. Publishing means calling the publish method on the open metadata interface.
There is also a withdraw method. This sets the governance zones of an element back to the default zones setting for its type. For example, if a number of changes need to be made to an element and while this is happening, the element should not be visible to general users, calling withdraw will set ip back to its initial zone settings. Once the updates are complete, the element can be published again to broaden its visibility.
Changing an element's visibility can be achieved by updating the elements zone membership through Classification Manager. The publish and withdraw methods externalize the list of zones that need to be set into ZoneMembership rather than having these values hard coded in various connectors and external programs.
Filtering query results using governanceZoneFilter¶
The Open Metadata View Services (OMVSs) have a governanceZoneFilter option on query requests that allow the caller to further restrict the elements returned based on their governance zone membership.
Note: This filtering is done after the security connector has filtered out elements that are not visible to the calling user.
Raise an issue or comment below
Anchor management (30 mins)
Anchors¶
Anchors are Referenceable metadata entities that group other entities together. They act like containers. This means, for example, if the anchor entity is deleted, all the entities anchored to this entity are also deleted. The value of establishing this grouping is to ensure that entities that have little meaning without their anchor entity are cleaned up properly and are not left to uselessly clutter the repository when the anchor is deleted.
Example: personal messages and profiles
For example, if a personal message is attached to a personal profile then that personal profile is its anchor. If the personal profile is deleted then the personal message is deleted too.
Anchored entities are also bound by the visibility and security restrictions of their anchor.
Example: Assets
For example, Asset visibility is controlled by governance zones. An Asset is only visible through a service if it is a member of that service's supportedZones. Similarly, authorization to perform specific operations on an Asset is granted by the Open Metadata Security Services. When a SchemaType is attached to an Asset, it is anchored to that Asset. Subsequent requests to read or update the SchemaType will result in visibility and authorization checks for the requesting user being made with respect to its Asset anchor.
The anchor is also important in templated cataloguing where an existing entity is used as a template to create another. When the template entity is an anchor, it and all the other entities that are anchored to it are duplicated to create the new entry and relationships are created to all other entities that are linked to the template and its anchored entities.
Finally, the organization of metadata elements using anchors is helpful in scoping searches.
Anchors classification¶
The Anchors classification contains the unique identifier (GUID) of an anchor entity. A GUID is attached to an anchored entity which makes it easier to navigate from an anchored entity to other entities anchored to it.
Example: SchemaElements and Comments
Figure 1 is an illustration of this example, with the addition of an Asset. The entities that have the Anchors classification are those that are anchored to the Asset. This includes entities such as Ratings, Likes and Attachments (from the Open Discovery Framework (ODF).

Figure 1: Examples of dependent entities that are anchored to an Asset
If a GlossaryTerm, or InformalTag is attached to an Asset through a relationship, they are not anchored to it. GlossaryTerms and InformalTags are independent entities. They are not anchored to the Asset and hence do not have an Anchors classification.
NoteLogs can be attached to many other Referenceables. They can be set up either to be anchored with a single Referenceable or to be their own anchor to allow then to be attached to and detached from many Referenceables over its lifetime.
Example: NoteLog and Referenceables
For example, these are cases where the NoteLog is anchored to another Referenceable
- NoteLogs are used to support the personal blog linked off of the Personal Profile in Community Profile OMAS.
- Assets may have a NoteLog to record "news" for consumers such as planned maintenance and unexpected situations.
Egeria uses the Anchors classification on a NoteLog to indicate that the NoteLog is tied to the Referenceable it is attached to. The presence of this classification would prevent it from being linked to another Referenceable.
Figure 2 is an illustration of the additional objects connecting to an asset that do not have the Anchors classification because they are not anchored to the Asset. Also notice there are two NoteLogs attached to the asset, one with the Anchors classification and one without. The one with the Anchors classification is anchored to the the Asset. The one without the Anchors classification is independent of the Asset.

Figure 2: Examples of other types of entities that are linked to an Asset but not necessarily anchored there
It is worthwhile maintaining the Anchors classification because reads of, and updates to the anchored entities will happen many times, and it is rare that an anchored entity will change its anchor during its lifetime.
LatestChange classification¶
The LatestChange classification is attached to Assets and GlossaryTerms. It is used to record the latest change to these types of entities and any of the entities anchored to them.
Example: LatestChange on Asset
So for example, if a hierarchy of SchemaElements, or a hierarchy of Comments, were anchored to an Asset, then the LatestChange classification is attached to the Asset and records changes to any of these entities. This includes changing property values, attaching or detaching entities through relationships as well as any changes to their classifications.
If a GlossaryTerm is attached to an Asset through a relationship, they are not anchored together since they each have an independent lifecycle. Any change to these entities does not reflect in the other's LatestChange classification. However, the act of attaching them to, or detaching them from, each other is recorded in both entity's LatestChange classification.
Maintaining the LatestChange classification on an Asset means that it is easier to monitor for changes affecting the Asset and any of its anchored entities. However, it also means that it must be easy to locate the Asset from any of the anchored entities when they change, even though they may not be directly connected.
Further information
- Generic Handlers maintain the Anchors and LatestChange classifications.
- Open Metadata Type definitions for LatestChange and Anchors classification
- Open Metadata security checks for Assets and Connections
- Governance Zones and Assets
Raise an issue or comment below
Working with templates (30 mins)
When a new resource is catalogued, the asset catalog entry of a similar resource can be used as a template to set up the asset for the new resource. The copying process extends to every entity, and its linking relationships that are anchored to the asset template, plus relationships to other entities outside of the anchoring scope. This means that the new asset can contain governance metadata attachments, not just the technical metadata extracted from the digital resource.
Templated cataloguing can be used for any type of element, not just assets. It has the advantages that:
- The resulting catalogued elements are much more consistent with one another making it easier for people to understand and work with.
- The increased consistency simplifies automation.
- Much of the complexity involved in creating a new catalog entry is hidden from the cataloguing user.
- Required classifications and governance relationships can be guaranteed to be included in each catalog entry.
An example¶
Peter Profile is responsible for cataloguing the weekly patient measurements supplied by the various hospitals as part of a clinical trial. These measurements come with with certain terms and conditions (also known as a license) that Coco Pharmaceuticals must not only adhere to, but prove that they are doing so. For that reason, when the measurements are catalogued, the asset for the measurements data set is linked to the license as well as other elements that help to ensure that the measurements data sets are appropriately used and governed.
Figure 1 shows Peter making calls to Egeria to catalog the first set of measurements received for the clinical trial. This includes an asset to represent the data set that is linked to the license along with a connection to allow the data scientist to connect to the data set and access the data and the schema showing the structure of the data in the data set. The data fields identified in the schema each link to the glossary term that describes the meaning of the data stored in the field. There are also two classifications on the asset:
- AssetZoneMembership - The governance zones that the asset is a member of. This controls who can access the asset and its related metadata elements such as the connection and the schema.
- Ownership - The owner of the data set. This is the person who is accountable for ensuring that Coco Pharmaceuticals adheres to the license.

Figure 1: In week 1, Peter manually creates the asset and links it to the governance elements needed to ensure the data set is used and protected as laid out in the license.
Without templating, Peter would need to issue the same sequence of (30+) requests to catalog each of the weekly results from each of the hospitals. This is a lot of work from Peter, particularly as the number of clinical trials, and participating hospitals rises. He may then make a mistake and forget one of the steps in the cataloguing process.
What if the catalog entry for the Week 1 measurements could be used as a template for cataloguing the subsequent weeks' measurements as shown in figure 2?

Figure 2: For subsequent weeks, the week 1 entry could be used as a template for cataloguing subsequent weeks. The result is an asset for each data set with a connection, a schema along with the ownership and zone membership classifications. All the assets are linked to the license and the data fields in each schema are linked to the correct glossary terms.
This is the idea behind templated cataloguing. A template that includes the common settings for a set of digital resources is defined and this template is used when cataloguing these resources.
Figure 3 shows a set of templates used by Coco Pharmaceuticals when cataloguing their digital landscape. There are different templates for different types of digital resources. Each would include the classifications and relationships that are relevant for the resources that they catalog. They are decorated with the Template classification to identify that they do not represent real digital resource and should be used as templates.

Figure 3: A set of templates defined to use when cataloguing digital resources
When a template is used in cataloguing a digital asset, the caller needs to supply the values that must be unique for the digital asset. This is typically the qualifiedName, displayName, description and may also include the networkAddress for its connection's endpoint. These values override those in the template.
Egeria uses the anchor classification to determine which elements linked to the template are duplicated and which elements are just linked to by the new catalog entry. In figure 2, for example, the connection and schema are anchored to the asset whilst the glossary terms and license are not. This means that copies of the connection and schema elements are made for the new catalog entry whilst the glossary terms and and licence just receive new relationships to the new catalog entry.
Finally, when a template is used, it is linked to the resulting element with the SourcedFrom relationship. This makes it easier to identity the elements that need changing if the template needs to be corrected or enhanced at a later date.

Figure 4: The
SourcedFromrelationship links a template to the elements that are created from it
Securing your metadata (1 hour)
Open Metadata Security¶
Open Metadata Security is optional. When it is activated, it provides fine-grained authorization services for open metadata services, types and instances. Since each organization will have different security requirements, the security support is implemented through connectors. Egeria defines the interfaces and when it will call the connector. You define the behavior the connector implements, and Egeria acts on the returned decision.
The metadata-security module defines the base classes and interfaces for the open metadata security connectors as well as the server implementation to host and call them.
There are two types of connector:
-
Platform metadata security connector - secures access to the administration and platform services. This includes the services to create new servers, the ability to start and stop servers as well as the ability to query whether a server is running, and if it is, what services are active.
-
Server metadata security connector - secures access to the specific services of an OMAG server. This includes access to the server's configuration document, starting and stopping the specific server, calling specific services, then within the server, access to specific Assets, Glossaries and Connections managed by the server, and finally the types and instances stored in the local repository.
The 2 types of connectors are shown in Figure 1:

Figure 1: positioning of the security connectors
Within an OMAG Server Platform there is one instance of the platform metadata security connector. This connector is configured either through the application.properties file before the platform is started, or using a REST API call once the platform is running.
Once it is in place, any call to the administration services or platform services results in a check to the platform metadata security connector.
The open metadata server security connector is optionally configured for each OMAG server, to allow for each server to have a different implementation.
The admin services command to configure a security connector for a server adds a connection for the server metadata security connector to the server's configuration document.
The platform and server metadata security connectors operate independently, depending on which service is called. However there is a hand-off whenever the server's configuration document is read, either as part of a configuration request, or a request to start the server.
As the request is received, the platform connector checks that the user has access to the platform. Assuming that is ok, the configuration document is read. If the configuration document contains the server metadata security connection, the connector is initiated using the connection. The server connector is then called to check that the calling user has permission to access the server.
This means that whenever the configuration document is called, the calling user has to have permission to access both the platform and the server. If the request is an administration service request, the user has to have administration access to the platform and server. If the request is to start the server, the user has to have operator access.

Figure 2: Calls to access a server's configuration document.
During a metadata and governance (OMAG) service call to a server, the security implementation in the server potentially invokes the server security connector multiple times as the request (shown as dotted white arrow) is handled by the server code. Figure 3 shows the different layers of checks. Each layer is optional and so the server security connector can be implemented to support the most appropriate granularity of security for the situation. Details of the implementation choices are given in the security connector API.

Figure 3: layers of security checks within the server
The security connectors are optional. If they are not defined then there are no additional authorization checks performed inside the OMAG Server Platform nor the OMAG Servers hosted on the platform. As such, it is important that the open metadata platform security connector is configured as soon as the platform is started, and the server security connector is configured before the server is started for the first time.
Metadata security APIs¶
Below is a description of the API of the two Open Metadata Security Connectors.
Open metadata platform security connector interface¶
The connector that plugs into the platform implements the following interface.
-
OpenMetadataPlatformSecurity - provides the interface for a plugin connector that validates whether a calling user can access any service on an OMAG Server Platform. It is called within the context of a specific OMAG Server Platform request. Each OMAG Server Platform can define its own plugin connector implementation and will have its own instance of the connector.
- validateUserForPlatform - Check that the calling user is authorized to issue a (any) request to the OMAG Server Platform.
- validateUserAsAdminForPlatform - Check that the calling user is authorized to issue administration requests to the OMAG Server Platform.
- validateUserAsOperatorForPlatform - Check that the calling user is authorized to issue operator requests to the OMAG Server Platform such as starting and stopping servers.
- validateUserAsInvestigatorForPlatform - Check that the calling user is authorized to issue requests for information to the OMAG Server Platform. For example, to validate a connector or request lists of registered services.
Open metadata server security connector interface¶
The connector that can be defined for an OMAG Server offers a series of layers of security checks. An organization can choose which layers to make use of and which to allow all requests to pass. Figure 2 shows the layers. Each layer is implemented in a separate interface and the connector can choose which interfaces to implement. Below are the interfaces and methods for the different layers:
OpenMetadataServerSecurity¶
OpenMetadataServerSecurity provides the root interface for a connector that validates access to Open Metadata services and instances for a specific user. There are other optional interfaces that define which actions should be validated.
- validateUserForServer - Checks that the calling user is authorized to issue a (any) request to the OMAG Server.
- validateUserAsServerAdmin - Checks that the calling user is authorized to update the configuration for a server.
- validateUserAsServerOperator - Checks that the calling user is authorized to issue operator requests to the OMAG Server.
- validateUserAsServerInvestigator - Checks that the calling user is authorized to issue operator requests to the OMAG Server.
OpenMetadataServiceSecurity¶
OpenMetadataServiceSecurity provides the interface for a plugin connector that validates whether a calling user can access a specific metadata service. It is called within the context of a specific OMAG Server. Each OMAG Server can define its own plugin connector implementation and will have its own instance of the connector. However, the server name is supplied so a single connector can use it for logging error messages and locating the valid user list for the server.
- validateUserForService - Checks that the calling user is authorized to issue this request.
- validateUserForServiceOperation - Checks that the calling user is authorized to issue this specific request.
OpenMetadataAssetSecurity¶
OpenMetadataAssetSecurity validates what a user is allowed to do with to Assets. The methods are given access to the whole asset to allow a variety of values to be tested.
- setSupportedZonesForUser - Provides an opportunity to override the deployed module setting of supportedZones for a user specific list.
- validateUserForAssetCreate - Tests for whether a specific user should have the right to create an asset.
- validateUserForAssetRead - Tests for whether a specific user should have read access to a specific asset.
- validateUserForAssetDetailUpdate - Tests for whether a specific user should have the right to update an asset. This is used for a general asset update, which may include changes to the zones and the ownership.
- validateUserForAssetAttachmentUpdate - Tests for whether a specific user should have the right to update elements attached directly to an asset such as schema and connections.
- validateUserForAssetFeedback - Tests for whether a specific user should have the right to attach feedback - such as comments, ratings, tags and likes, to the asset.
- validateUserForAssetDelete - Tests for whether a specific user should have the right to delete an asset.
OpenMetadataConnectionSecurity¶
OpenMetadataConnectionSecurity defines the interface of a connector that is validating whether a specific user should be given access to a specific Connection object. This connection information is retrieved from an open metadata repository. It is used to create a Connector to an Asset. It may include user credentials that could enhance the access to data and function within the Asset that is far above the specific user's approval. This is why this optional check is performed by any open metadata service that is returning a Connection object (or a Connector created with the Connection object) to an external party.
- validateUserForConnection - Tests for whether a specific user should have access to a connection.
- validateUserForAssetConnectionList - Selects an appropriate connection for a user from the list of connections attached to an Asset.
OpenMetadataGlossarySecurity¶
OpenMetadataGlossarySecurity validates that a specific user is authorized to perform various operations on a glossary and its contents (terms and categories).
- validateUserForGlossaryCreate - Can the user create a new glossary?
- validateUserForGlossaryRead - Can the user have read access to a specific glossary and its contents?
- validateUserForGlossaryDetailUpdate - Can the user have the right to update the properties/classifications of the top-level glossary object?
- validateUserForGlossaryMemberUpdate - Can the user have the right to update the terms and categories of a glossary? These updates could be to their properties, classifications and relationships. It also includes attaching valid values but not semantic assignments since they are considered updates to the associated asset.
- validateUserForGlossaryMemberStatusUpdate - Can the user have the right to update the instance status of a term anchored in a specific glossary?
- validateUserForGlossaryFeedback - Can the user have the right to attach feedback - such as comments, ratings, tags and likes, to the glossary, or its terms and categories.
- validateUserForGlossaryDelete - Can the user delete a glossary and all its anchored contents, such as its terms and categories.
OpenMetadataRepositorySecurity¶
OpenMetadataRepositorySecurity defines security checks for accessing and maintaining open metadata types and instances in the local repository. An instance is an entity or a relationship. There is also a special method for changing classifications added to an entity.
- validateUserForTypeCreate - Tests for whether a specific user should have the right to create a typeDef within a repository.
- validateUserForTypeRead - Tests for whether a specific user should have read access to a specific typeDef within a repository.
- validateUserForTypeUpdate - Tests for whether a specific user should have the right to update a typeDef within a repository.
- validateUserForTypeDelete - Tests for whether a specific user should have the right to delete a typeDef within a repository.
- validateUserForEntityCreate - Tests for whether a specific user should have the right to create an instance within a repository.
- validateUserForEntityRead - Tests for whether a specific user should have read access to a specific instance within a repository. May also remove content from the entity before it is passed to caller.
- validateUserForEntitySummaryRead - Tests for whether a specific user should have read access to a specific instance within a repository.
- validateUserForEntityProxyRead - Tests for whether a specific user should have read access to a specific instance within a repository.
- validateUserForEntityUpdate - Tests for whether a specific user should have the right to update an instance within a repository.
- validateUserForEntityClassificationUpdate - Tests for whether a specific user should have the right to update the classification for an entity instance within a repository.
- validateUserForEntityDelete - Tests for whether a specific user should have the right to delete an instance within a repository.
- validateUserForRelationshipCreate - Tests for whether a specific user should have the right to create an instance within a repository.
- validateUserForRelationshipRead - Tests for whether a specific user should have read access to a specific instance within a repository. May also remove content from the relationship before it is passed to caller.
- validateUserForRelationshipUpdate - Tests for whether a specific user should have the right to update an instance within a repository.
- validateUserForRelationshipDelete - Tests for whether a specific user should have the right to delete an instance within a repository.
- validateEntityReferenceCopySave - Tests for whether a reference copy should be saved to the repository.
- validateRelationshipReferenceCopySave - Tests for whether a reference copy should be saved to the repository.
OpenMetadataEventsSecurity¶
OpenMetadataEventsSecurity defines security checks for sending and receiving events on the open metadata repository cohorts.
- validateInboundEvent - Validates whether an event received from another member of the cohort should be processed by this server. May also remove content from the event before it is processed by the server.
- validateOutboundEvent - Validates whether an event should be sent to the other members of the cohort by this server. May also remove content from the event before it is sent to the cohort.
Sample connectors¶
There are sample implementations of the security connectors for Coco Pharmaceuticals in the "samples" module under open-metadata-security-samples
Raise an issue or comment below
Linking metadata governance to your governance program (1 hour)
Setting up your Governance Program¶
An organization's governance program described the cross-cutting initiatives that ensure the organization is operating efficiently and ethically with the most optimal use of resources. Egeria supports open metadata definitions that aid the management and exchange of information with different tools and systems that drive the governance program.
The governance program is divided into governance domains.
Governance domains¶
Governance domains are the areas of an organization's operation that need a specific governance focus. For example, a governance domain may be driving a transformation strategy, planning support for a regulation, driving an efficiency campaign or developing an assurance program for your organization.
A governance domain typically involves the ongoing cooperation of multiple teams from different business areas. There is often a business strategy and a set of targets associated with the domain since its purpose is to provide some level of improvement or benefit to the organization.
Each domain is typically the responsibility of a different executive in the organization. Different domains may use slightly different terminology and often run different tools but in fact they are very similar in the way that they operate. Egeria allows the teams from the different governance domains to collaborate and benefit from each other's efforts.
Examples of governance domains
The governance domains can vary in scope and importance to the business. In the example below, Corporate Governance ensures that the business operates legally. It is the key focus of the board or directors and includes financial reporting.
At the heart of the organization's operation are three governance domains that are often run separately, but in fact are highly dependent on one another:
- Data (or Information) Governance focuses on the appropriate use and management of data.
- Information Security (InfoSec) focuses on the security of the IT Systems (and sometimes the physical security of buildings and plant).
- IT Infrastructure ensures systems are correctly set up and managed.so they deliver the level of service required by the business. This governance domain often uses a taylored version of IT Infrastructure Library (ITIL).
Software development needs governance to ensure it is properly designed, built and tested - and fit of purpose. This governance is typically guided by a software development method, such as Agile Development and covers all aspects of the software development lifecycle.
There are other domains that are more specialized. For example:
- Privacy focusses on compliance with data subject privacy. It interacts with the data governance, software development lifecycle and IT Infrastrcuture domains.
- Human Capital Management combines Human Resources (HR) and the management team of the organization to ensure the people they employ receive the training and support to build the right skills to support the business.
- Risk Management assesses and, where necessary mittigates against the risks that may impact the organization. It is often lead by the finance team because the level of risk can affect their credit rating. However in some industries, such as banking, where the reporting and management of risk is covered by specific regulations, there is a separate organization that interfaces with the regulators.
- Physical Asset Management manages the physical buildings, furnature, machinery, computers etc that the organization owns. It is responsible for maintenance and replacement of these items.
- Product Assurance ensures the products that the organization sells meet regulatory requirements and match the ethos of the organization.
- Procurement focussed on the policies and rules assicuated with the products and services bought by people across the organization. There may be a seprate procurement team that interacts with suppliers to ensure bulk discounts and quality. They would work with other leaders in the organization to ensure the approach matches the needs of the business.
- Sustainability is a relatively new governance domain that focuses on the effective use of resources to improve long-term sustainability of the organization's operations.

Examples of different governance domains within an organization.
Governance domains are represented by Valid Value Definition entities in open metadata. They are organized into a ValidValueSet collection using the Valid Metadata Values services.

The governance domain descriptions organized in a valid value set under the
domainIdentifierattribute
The governance domain descriptions include the preferredValue for the domainIdentifier property, a displayName and a description. The domainIdentifier property is an integer and by convention "0" means "applies to all domains". For example:
| Domain Identifier | Display Name | Description |
|---|---|---|
| 0 | All | Governance program leadership and shared definitions. |
| 1 | Data | The governance of data and its use. |
| 2 | Privacy | The support for data privacy. |
| 3 | Information Security (InfoSec) | The governance that ensures IT systems and the data they hold are secure. |
| 4 | IT Infrastructure | The governance of the configuration and management of IT infrastructure and the software that runs on it. |
| 5 | Software Development Lifecycle | The governance of the software development lifecycle. |
| 6 | Corporate Governance | The governance of the organization as a legal entity. |
| 7 | Physical Asset Management | The governance of physical assets. |
Defining governance domains
Governance domain descriptions can be defined in an Open Metadata Archive or through the Valid Metadata OMVS.
Governance Leadership¶
A governance domain needs a leader to drive the change and focus that it demands. When an organization decides to create a new governance domain, the appointment of the leader of the domain is the first decision. This person then organizes the people and resources that will drive the definition and rollout of changes needed to make the governance domain successful.
The leadership of the governance domain is a type of governance role.
Governance Roles¶
Governance roles define the additional responsibilities and tasks that people need to do in order to make the governance domain successful. These roles lead initiatives or take ownership of resources. Some governance roles are full-time jobs, but most will be a few hours from time to time. The governance roles are identified and defined as the operation of the domain is worked out. This includes specifying the responsibilities so that an assessment of the cost/benefits can be made. People are appointed to the roles later, as the governance domain is put into operation.
Egeria defines a set of governance role types to provide a framework for your governance roles. Governance roles have a domainIdentifier property to identify that the role is defined for a particular domain. You create instances of these types to define the roles for the domain. For example, there is a governance role type called AssetOwner. You may want a role that is responsible for granting access to a data asset. So you may create a role of type AssetOwner called Asset access manager with responsibilities for approving requests to access the data.
Multiple people may be assigned to a role. So you can choose to define generic roles and appoint multiple people to them. Alternatively, if you want to define precisely which resources they are responsible for, then you need more fine-grained roles.
For example, you may have 100 data assets and each needs at least one person to grant access to it. Here are some different choices on how you could set this up.
-
You may choose to have one Asset access manager role and appoint a small group of people to the role. These people can grant access to any of the 100 data sets.
-
You may want to organize the data assets into different groups and appoint different people to grant access to the assets in each group. In this case, you would have a governance role instance for each group. They would be linked to the element that represents the group via the AssignmentScope relationship.

- You may want to have specific roles for each data asset. This could be a lot of overhead to defined roles explicitly. You could choose to have a generic role where the appointment and scope is handled via the Ownership classification.

These different approaches allow you to have enough detail in your open metadata definitions to configure tools and report on governance activity, whilst minimising effort to keep the definitions up to date.
Representing governance roles in open metadata
Governance roles are types of PersonRole. They link to a governance responsibility (a type of governance definition using the GovernanceResponsibilityAssignment relationship). The profile of a person is linked to the governance role using the PersonRoleAppointment.

The Governance Officer OMVS supports the setting up of governance roles. The People Organizer OMVS supports the appointment of people to roles.
Governance Leadership Communities¶
The governance domain covers activity occurring in different parts of the business. The people working for the domain will not be reporting directly to the governance domain leader - they continue to report through their line of business. Therefore, the governance domain leader needs a mechanism to bring people together, share progress and the latest information. This can be done through a community.
Governance Domain Communities¶
Each governance domain would typically have a community, led by the governance domain leader and with a membership consisting of the people appointed to the governance roles supporting the governance domain.

As the governance roles are defined, they are added to the governance domain community using the CommunityMembership relationship. As people are appointed to the roles, they automatically become a member of the community.
Governance Leaders Community¶
Often the leaders of the governance domains need a forum to share ideas and collaborate. This can be achieved by setting up a community for the governance leaders. This means the governance domain leader is the head of their governance domain community and is a member of the governance leadership community.

Defining the governance communities' membership in Egeria means that as people are appointed or removed from roles, Egeria can automatically maintain access control lists and email list for the membership.
Governance domain management process¶
Most activity within each governance domain is iteratively developed and reviewed. Managing the governance domain includes:
-
Designing how the governance domain will operation:
-
Understanding the business drivers and regulations that provide the motivation and direction to the governance program.
-
Laying down the governance policies (principles, obligations and approaches) that frame the governance program.
-
Planning and defining the governance controls that detail how these governance policies will be implemented in the organization, and enumerating the implications of these decisions and the expected outcomes.
-
Defining the organization's roles and responsibilities that will support the governance program.
-
Defining the classifications and governance zones that will organize the assets being governed.
-
Defining the subject areas that will organize the data-oriented definitions such as glossary terms, valid values and quality rules.
-
Defining the governance metrics that will measure the success of the governance domain.
-
Defining the execution points that identify how the governance domain's decisions and actions taken are to be implemented.
-
Planning the rollout of changes to both the organization, processes and technology that will drive the governance domain.
-
-
Reviewing the impact of the governance activity against the goals of the governance domain.
- adjusting governance implementation as necessary.
-
Reviewing the strategy, business and regulatory landscape.
-
adjusting the governance definitions and metrics as necessary.
Governance Definitions¶
A Governance Definition is a metadata element that describes the context or purpose for an activity that supports the organization's operation. The picture shows the main types of governance definition and how they link together to create a coherent response to a business strategy or regulation.

Using governance definitions to provide traceability from business drivers and regulations to actions.
Subject areas¶
Subject areas are topics or domains of knowledge that are important to the organization. Typically, they cover types of assets (such as data) that are widely shared across the organization and there is business value in maintaining consistency in the data values in each copy.
The role of a subject area definition is to act as a collection point for all the subject area materials. This includes:
- A glossary of terms that describe the key concepts in the subject area.
- Lists and hierarchies of reference data that relate to particular data values in the subject area.
- Quality rules for specific data values in the subject area.
- Preferred data structures and schemas.
The materials that are part of the subject area are classified as such using the SubjectArea classification.

Defining a subject area
Each subject area has an owner (see SubjectAreaOwner) who is responsible for the materials relating to the subject area. Often the subject area owner is a senior person in the organization with expertise in the subject area. He/she coordinates other subject-matter experts to author and maintain the materials and their use. It is helpful to set up a community of people working on the subject area's materials, to coordinates email distribution lists, news and events.

People working on a subject area come together in a community
The subject area definition can be linked to governance definitions via the GovernanceBy relationship.
The organization of the subject areas is orthogonal to the governance domains. Some subject areas are common to multiple governance domains; others are specialized within a governance domain. Similarly, an organization can create governance definitions that are applicable to all subject areas, or are specific to the subject area they are linked to. Typically, they will have a mixture of these.
Further information
-
Common Data Definitions describes the management and use of subject areas.
-
The Defining Subject Areas scenario for Coco Pharmaceuticals walks through the process of setting up the subject areas for Coco Pharmaceuticals.
-
There are two code samples associated with this set of subject areas:
- Setting up the subject area definitions
- Setting up glossary categories for each subject area ready for subject area owners to start defining glossary terms associated with their subject area.
-
Governance Officer OMVS supports the setting up of subject area definitions.
- Reference Data OMVS supports the definition of reference data for the subject area.
- Data Designer OMVS supports the definition of data requirements for the subject area.
- Asset Manager OMAS supports the management of glossaries and the exchange of subject area information with other catalogs and quality tools.
Governance classification, tagging and linking¶
One of the ways to reduce the cost of governance is to define groups of similar assets/resources along with the governance definitions that apply to members of the group. This avoids having to make decisions on how to manage each asset/resource. The cataloguing process just needs to work out which group(s) to place the asset in. Labels such as classifications, and tags of different types are used to identify these group assignments. When a governance process is operating on the asset/resource, it looks up the labels and follows the governance definitions for the group.

Figure 4: Different types of tags used to group assets for governance
The different types of labels used to group assets/resources are used for different purposes and may indicate how official they are:
-
Governance Zones group assets according to their use. They are typically is used for controlling visibility to the resource's asset definition.
-
Governance Classifications define the groups used for specific types of governance.
- Confidence Governance Classification defines the level of confidence that should be placed in the accuracy of related data items. This limits the scope that the data can be used in.
- Confidentiality Governance Classification defines the level of confidentiality or secrecy needed with particular data.
- Criticality Governance Classification defines how critical the related resources are to the continued operation of the organization.
- Impact Governance Classification defines how much of an impact a particular situation is to the operation of the organization.
- Retention Governance Classification defines how long a resource (typically data) must be retained by the organization.
-
License Types define the contract aka (terms and conditions) that define how the asset/resource can be used.
-
Certification Types define specific characteristics of an asset/resource that has been verified for a particular span of time.
-
SecurityTags identify labels and properties that are used in determining which data protection rules should be executed when particular data is requests. They can be attached to assets or schema elements depending on the scope of data that the security tags apply to. The synchronized access control feature describes how security tags are set up and used.
The labels may be assigned directly to the asset, or to elements, such as schemas and glossary terms that are linked to the asset.
Setting up the levels for your governance classifications¶
The values used in governance classifications show the specific group that the classified asset belongs to. Often an organization has their own levels defined, and they can be set up using the valid metadata values definitions.

Figure 5: Governance classifications that use governance level definitions
Egeria has a set of default values that can be set up using the createStandardGovernanceClassificationLevels method.
Measures and metrics¶
As important aspect of the governance program is the ability to measure its effectiveness and identify the assets that are delivering the highest value, or operating with the greatest efficiency etc.
A value that should be captured to demonstrate the effectiveness of the governance program is documented using the GovernanceMetric entity. It is linked to the appropriate governance definition and can be linked to a data set where the specific measurements are being gathered.
The calculation of governance metrics is often a summary of many other measurements associated with specific resources (such as data sources and processes) operating under the scope of the governance program. These resources are catalogued as Assets.

Figure 6: Measuring governance through an external data set
The definition of their expected behavior or content can be captured using the GovernanceExpectations classification attached to the Asset. The measurements that support the assessment of a particular resource can be gathered and stored in a GovernanceMeasurements classification attached to its Asset.

Figure 7: Setting expectations and gathering results in classifications
The measurement classification may be attached to a related element that describes an aspect for its operation. For example, in figure 8 the measurement is attached to a process instance that captures a specific run of a process. The expected values are attached to its parent process.

Figure 8: Attaching the measurements to related elements
Execution points¶
A governance execution point defines specific activity that is supporting governance.
There are three types:
-
A Control Point is a place in the processing where a decision needs to be made. It may be a choice on whether to tolerate a reported situation or to resolve it - or it may be a decision on how to solve it.
-
A Verification Point describes processing that is testing if a desired condition is true. Quality rules are examples of verification points. The result of a verification point is the output of the test. It may, for example, be a boolean, classification or a set of invalid values.
-
An Enforcement Point describes processing that enforces a specific condition. For example, data may need to be encrypted at a certain point in the processing. The encryption processing is an enforcement point.
The ExecutionPointDefinition elements are created during the design of the governance program. They characterize the types of execution points that are needed to support the governance requirements. They are linked to the Governance Definition that they support using the ExecutionPointUse relationship. Typically, the governance definitions linked to the governance execution point definitions are:
- Governance Processes
- Governance Procedures
Often execution points need to be integrated with the normal activity of the business, but they may also represent additional standalone activity.
The classifications ControlPoint, VerificationPoint and EnforcementPoint are used to label governance implementation elements with the type of execution point and the qualified name of the corresponding definition if any. They are often found on element such as:
- Governance Action Process Steps
- Engine Actions
These classifications help in the review of the implementation of the governance program and can be used to drive additional audit logging.

Implementing the actions defined in your governance definitions.
Governance Rollout¶


Open metadata implementation¶
How the Open Metadata Access Services (OMASs) support the governance program
-
The Governance Program OMAS supports the setting up of governance domain and its associated definition elements.
-
The Community Profile OMAS supports the definition of the profiles for people and teams that will support the governance program. These are linked to the governance roles defined by the governance program.
-
The Project Management OMAS supports the rollout of the governance program by commissioning campaigns and projects to implement the governance controls and the collection of measurements to assess the success of the program.
-
The Digital Architecture OMAS provides the setup of the digital landscape that supports the governance program. This includes the definitions of the information supply chains and solution components that support the organization's activities.
-
The Digital Service OMAS documents the business capabilities along with their digital services that are supported by the governance program.
-
The Governance Server OMAS supports the implementation of technical controls and the choreography of their execution.
-
The Stewardship Action OMAS supports the stewards as they manage the exceptions detected to the governance program.
-
The Data Manager OMAS support the automated cataloging of assets and configuration of technology that is managing them.
-
The Security Manager OMAS support the configuration of technology that is managing the security of assets.
-
The Asset Manager OMAS supports the automated exchange of governance definitions between catalogs and asset managers to create a consistent rollout of governance requirements.
-
The Asset Owner OMAS supports the linking of governance definitions and classifications to assets to define how they should be governed.
-
The Asset Consumer OMAS supports the visibility of the governance definitions and classification by consumers of the assets.
The egeria-samples.git repository includes a sample called Sample metadata archives for Coco Pharmaceuticals that creates open metadata archives with basic definitions for Coco Pharmaceuticals. This includes the definition of this organization's governance domains with their communities and governance officers.
Raise an issue or comment below
Raise an issue or comment below