Common data definitions¶
Common data definitions (also known as the common information model or CIM) create a shared understanding of the data in a topic area. They are critical where data is to be shared between different systems and or groups of people.
Typically, the common data definitions consist of:
- Names and descriptions for concepts described by the data.
- Relationships between these concepts.
- Classifications of the concepts to indicate how they are used.
- Definitions of the valid data values for specific concepts and associated governance rules.
- Preferred logical and physical data formats for storing data about these concepts.
The common data definitions in open metadata are part of the Subject Area Materials and are grouped into subject areas. The core materials that cover the meaning of data are described in one or more glossaries. These are augmented by valid values, reference data and quality rules.
Governed data classifications may be added to these definitions which in turn link to governance requirements. This determines how data that is linked to the subject area material should be governed.
Tools used by the organization to, for example, create new data stores, data visualizations, or APIs, or analytics models are pre-populated with concrete data definitions by automated tool bridges. Each tool bridge extracts the relevant definitions from the metadata catalog, generates the concrete definitions and loads them into the tool. Where possible, these definitions include tags that link the definitions back to the common data definitions.
When the new IT capability is deployed to test and production environments, the tool typically produces a packaged version of the concrete definitions with their tags that point to the metadata. The dev-ops pipeline that deploys the artifact reads the tags and ensures that any specific governance requirements for the specific type of data that is being used are met.
Once the new capability is running, the IT infrastructure that is supporting it can be using the tags, and related metadata deployed to the production environment to manage the governance related to the capability, and, where the capability is also using metadata directly, to drive the function and data delivered to its consumer.
Figure 1 summarizes this process for using subject areas and their associated material.
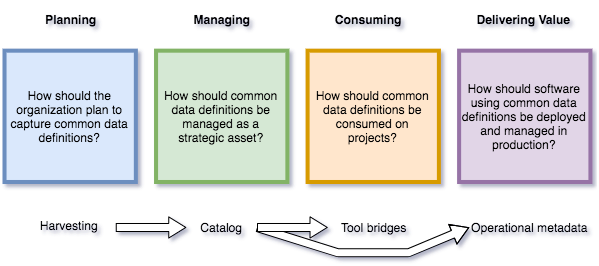
Figure 1: process for using common data definitions
The four boxes in figure 1 show the activity around managing the subject area materials and below them are the tools and processes using them. Typically, all 4 activities are running continually as the scope of the subject areas typically starts small and expands as new projects consume them.
The harvesting activity is locating and extracting content for the subject area materials from existing sources. These may be definitions created by the organization for previous projects or definitions from external sources. They need to be validated and transformed, so they can be injected into the catalog used to manage the definitions.
The managing activity describes the efforts of the subject-matter experts to import, create and maintain the subject area materials into a catalog. Typically, the appropriate subject-matter experts are assigned to each subject area.
The consuming activity is where the subject area materials are transformed and made available in tools that are being used to build or maintain new capability.
The delivering value activity is where the subject area materials are being used to deliver business function and governance in the production systems.
Further information
Raise an issue or comment below