Duplicate Management¶
Duplicate management identifies multiple metadata instances that represent the same concept or resource. These duplicate instances, as they are called, occur when the same concept or resource is captured in multiple tools. They are not noticed as duplicates when the tools operate independently. However, when these tools are connected together through Egeria, the duplicates are shared. The result is the appearance of more resources than there are, and any inconsistencies between them can lead to possible errors in decisions made using this information.
It is rarely possible to simply delete all but one of the duplicate instances because each copy is often needed by its originating tool. Egeria needs a mechanism to handle these duplicates.
Egeria's duplicate management ensures duplicate instances are linked and classified so that on retrieval, the information from the duplicates is combined to give a meaningful result.
Examples duplicate instances¶
Figure 1 shows a simple case where each duplicate instance originates from a different tool. Although each instance has a different unique identifier (GUID), the rest of the metadata is consistent. This makes it easy to spot when both are returned in a search query. However, a query to count, say, the number of glossary terms would give misleading results.

Figure 1: Two copies of the same glossary term originating from different repositories
When related information is required (for example, which assets are linked to the glossary term customer) the request needs to be issued for each duplicate instance to retrieve the complete picture. Figure 2 shows that the users of one tool have linked their copy of the glossary term to assets 1 and 2 whereas the users of the other tool have linked their copy of the glossary term to asset 3.

Figure 2: Different sets of relationships associated with each duplicate
Some duplicates are not so easy to identify. Figure 3 shows an example of duplicate assets where the values in the assets are different, but the fact that they describe the same resource can be deduced by the fact that the related endpoints point to the same location.

Figure 3: Duplicate assets identified through their endpoints
In some circumstances the tools are correctly cataloguing the existence of two resources however the resources themselves are duplicates of one another. Figure 4 shows two copies of the same image. The tools record the name of each copy but have no knowledge that their contents are the same.
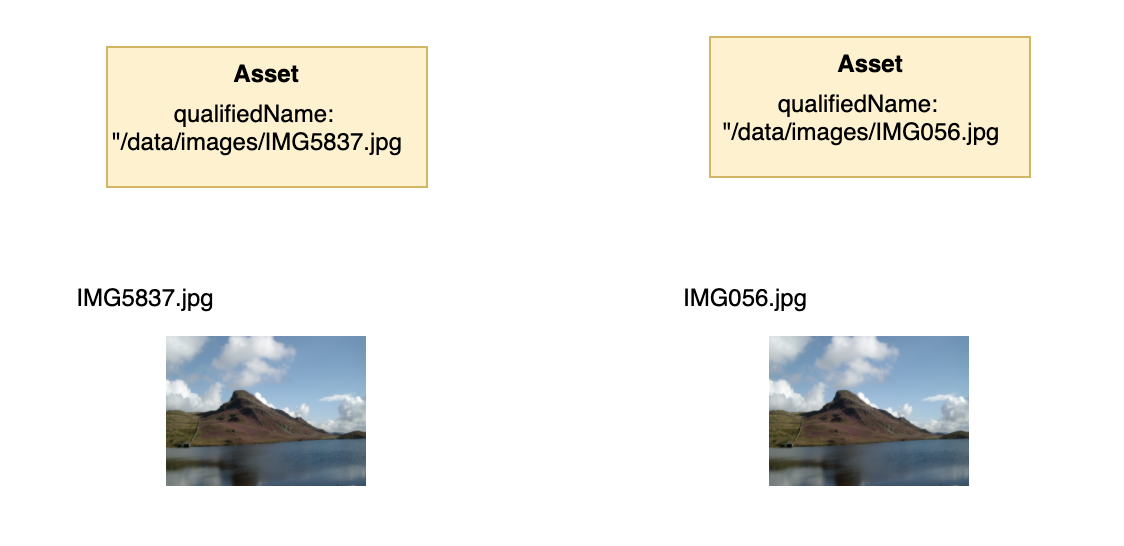
Figure 4: Two copies of the same resource are catalogued as two assets. There is no shared values in the metadata.
Avoiding duplicates¶
Duplicates can add a significant burden to your data processing. Therefore, there is value in controlling the copying of data and ensuring that resources are catalogued only once. However, some duplication can not be avoided and Egeria has mechanisms to handle them.
How are duplicates managed in Egeria?¶
Duplicate management has four parts to it:
- Detecting duplicate resources
- Detecting duplicate metadata entries for the same resource or concept.
- Linking duplicate instances together so that they can be processed together.
- Combining duplicate instances so that they can be retrieved as if they were one.
Figure 5 shows the architecture of an Egeria duplicate management solution.

Figure 5: Components in a deduplication solution include the cohort members that are supplying the duplicates and retrieving metadata along with the engine host that is running the governance engines detecting and managing duplicates in conjunction with the stewards
The numbers on the diagram refer to the following points:
-
These are the tools that are potentially introducing duplicates into the cohort. In this example they are connected through repository proxies and are not capable of storing reference copies of metadata. This means the duplicates that they collectively introduce must be managed for the benefit of other consumers of the metadata.
-
Metadata Discovery analyses the content of resources and so can be used to detect duplicate resources (as opposed to duplicate catalog entries for the same resource). There are algorithms for producing a fingerprint (like a hash) that represents the content of each resource. These fingerprints can be stored as annotations attached to the resource's asset via a survey report. These fingerprint annotations are metadata that can be automatically analysed during duplicate detection.
-
The examples in figures 1-4 show that the mechanisms to detect duplicates are varied and often require knowledge of the data management practices in the organization. As such this function must be pluggable into Egeria's runtime. Engine Actions monitor for changes in metadata and search for duplicate instances. They link detected duplicates together.
-
A governance action, possibly the same one that detected the duplicates, can validate and action the duplicates so that survivorship processing occurs when they are retrieved from the metadata repositories (see step 6).
-
Alternatively, the duplicates can be validated and actioned by a steward.
-
When a service detects duplicates during a request to retrieve metadata from the repositories it automatically processes the duplicates so the caller is not aware that the duplicates exist.
Figure 6 shows an example of a governance action process that controls the governance actions and the use of the stewards for duplicate detection.

Figure 6: The steps in an example governance action process
There is a watchdog governance action that is monitoring for new assets. It initiates a verification governance action to detect any duplicates for each new asset. Each verification governance action produces a guard whose value depends on the confidence that it has in the accuracy of any detected duplicates:
no-duplicateguard means it discovered no duplicates and so the process stops.link-duplicatesguard means it is very confident that it has detected a duplicate and so it can be actioned automatically by a remediation governance action before the process stops.validate-duplicatesguard means that a steward should verify that duplicates have really been detected. This is achieved by a triage governance action creating aToDoand a watchdog governance action waiting for the steward to complete the ToDo before stopping. The steward uses the Classification Manager API to verify and set up the duplicates.
Duplicate management styles¶
Egeria has two styles of duplicate management that can be actioned automatically or by a steward. They are peer linking and consolidation. The open metadata types used in both styles are defined in model 0465 Duplicate Management.
Peer linking¶
When duplicate entities are first detected by a governance action, they are linked together by the PeerDuplicateLink relationship. This relationship includes properties that indicate how confident the detecting process is that the entities are duplicate instances. No change occurs in the retrieval of these instances at this point.
If a steward or automated process confirms the duplicate instances are correctly identified, KnownDuplicate classifications added to the entities tell the metadata retrieval functions to automatically combine the content of the duplicates when any of them is requested. This is peer linking.
Consolidation¶
Consolidation is the process where the combined results of the duplicates is pre-calculated, stored as a new entity and linked to the duplicate instances using the ConsolidatedDuplicateLink relationship. The assessment of confidence of the deduplication is stored in the ConsolidatedDuplicate classification on the instance that contains the combined results.
Metadata retrieval of duplicates¶
When an Egeria retrieval operation is requested by an Open Metadata Access Service (OMAS), it monitors for the KnownDuplicate classification on the entities it is retrieving. When found, and the retrieval request is not part of duplication management, deduplication occurs.
Deduplication¶
During deduplication, the retrieval process first looks for the ConsolidatedDuplicateLink relationship. If that is found, the consolidated instance is returned instead. If not, the instances linked via PeerDuplicateLink relationships are combined. The combination process requires choices to be made on which values to use. These choices are called the survivorship rules.
Survivorship rules¶
The survivorship rules operate on the following principles:
- Newer metadata is more accurate.
- The cardinality of relationships must be respected.
- If multiple peer entities point to the same target entity with the same type of uni-link relationship then the target entity is processed only once.
Figure 7 shows two glossary terms linked as peer duplicates. When an entity is queried by GUID, properties from the most recently updated duplicate instance are returned with a combination of classifications. Conflicts in classifications are recorded on the audit log. The latest values from the conflicting classifications are used.
When the relationships of an identified duplicate are queried, the combination of relationships from all duplicate entities is returned unless only one instance of a relationship is allowed in which case the latest values are used.

Figure 7: Peer duplicates with distinct relationships
Figure 8 shows that both glossary terms link to the same schema attribute using the SemanticAssignment relationship. Although this relationship has a cardinality of many-to-many, it is uni-link so only the newest relationship is processed.

Figure 8: Peer duplicates pointing to the same entity via the same type of uni-link relationship
Figure 9 shows a consolidated duplicate linked to the glossary terms. If any of these three entities are requested the consolidated duplicate is returned.

Figure 9: Peer duplicates linked to a consolidated duplicate
Note: survivorship rules only operate on instances with appropriate effectivity dates.
Raise an issue or comment below