Data quality¶
Data quality is the degree to which data meets the needs of its consumers. There is no absolute definition of quality and an improvement in data quality for one team may be a decrease in data quality for another.
Data quality can be assessed along different dimensions such as:
- Correctness - how factual it is?
- Completeness - are all data values for the collection gathered?
- Precision - does it include sufficient level of detail?
- Timeliness - is it available for processing when needed?
- Relevance - is the context in which the data was gathered sufficiently close to the data needs of the consumers to be useful?
- Scope - does the data cover the scope of the problem space?
- Credibility - do the consumers believe the values in the data?
- Traceability - can it be shown it comes from a credible source and any processing it has undergone is valid?
Data quality needs to blend various techniques to deliver quality to each consumer. Aspects of data quality need to be applied throughout the information supply chain.
Consider an information supply chain that has these types of data sets in it
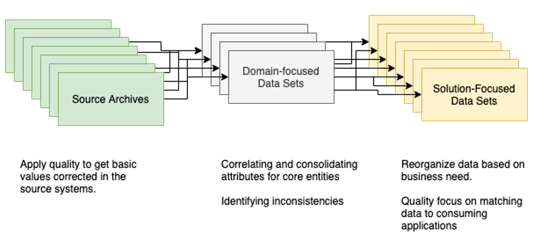
At each stage in the information supply chain, different sets of quality rules can be applied.
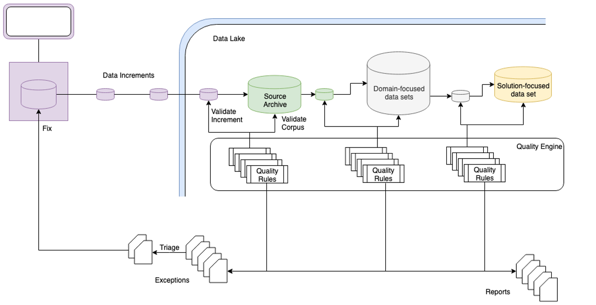
Detected errors are captured as exceptions and routed to the appropriate stewards.
Data quality management process¶
The management of data quality involves:
-
Understanding the source data values - Analysing the data content of a digital resource, typically running survey action services, to get an assessment of the data values it contains. This may be simple fact gathering using data profiling or executing quality rules to determine how well it fits to the data specifications needed for its different purposes.
-
Adding context to the data - Using the findings from the open discovery service to assign additional classifications and links that help to identify the data as fit for the different purposes. This assignment may be by an automated process or human curation and ensures the data resource will appear in the search results of related data catalog queries.
-
Correction of unexpected anomalies in the data values to bring the data inline with the desired specification(s).
-
Extending data quality capability - Using the profiling to set up new data classes and quality rules.
Achieving data quality is a complex subject, and can be expensive. It needs to be approached with a clear view on the business value of the data, the context in which it was gathered, and the purpose(s) to which it is to be used to be sure an appropriate level of investment is made.
Understanding data values¶
One of the potentially most expensive parts of data quality is to capture a full understanding of the data values in a data source. Much of this should be done by the creators of the data, but for many organizations, this is not routinely gathered and the data management teams needs to recreate this context using a variety of techniques. Typically, knowledge of the data grows over time.
Understanding the structure of data¶
Consider this data:

It is possible to guess what some values mean, but there are often many fields that incomprehensible.
The first stage to understanding data is to determine if it has a schema that will show its structure, revealing individual data items.

The schema helps in the understanding of where the data fields, and in some cases, it is possible to understand the meaning of the data values.
When the data source is catalogued in open metadata, an abstract representation of the schema is captured as Schema Elements. These schema elements include Schema Attributes that represent the data fields and their associated Schema Types that record the actual data types used in the data.

Adding context to the data¶
Open metadata provides mechanisms to augment the asset and its schema with context information that guides the data quality processes.
- Data classes - these are logical types for the data.
- Semantic assignments - these are links to glossary terms that describe the meaning of typically a data field, but may also be assigned to describe the meaning of the data resource as a whole.
- Origin and lineage can be added to indicate scope and the context of the data source.
In the diagram below, the Employee Data Of Birth glossary term is linked to a data class called Adult Data Of Birth. This detects that a date of birth is not only a valid date but also describes someone older than 18 years old. The sample data shown below includes a date of birth of a young infant. Either the date of birth is incorrect, or this individual should not be an employee!

Correction of data¶
The execution of data quality rules can be embedded into open discovery services and the results recorded in QualityScoreAnnotations.
Any errors detected can result in a request for action that notifies an appropriate steward to correct the data.
Alternatively, an error may be corrected automatically using reference data.
Extending data quality capability¶
The process of data profiling captures list of data values found in a data source. These values can be mined to create candidate data classes and valid value sets to use in future data quality assessments.
Further information
Raise an issue or comment below