In development
A component that is in development means that the Egeria community is still building the function. The code is added continuously in small pieces to help the review and socialization process. It may not run, or do something useful - it only promises not to break other function. Expect to find git issues describing the end state.
Hive Metastore Repository Connector¶
This repository has been created to manage artifacts and issues relating to integration with Hive Metastore (HMS). This connector is based on the same polling pattern that the File sample OMRS connector uses.
Connector details
- Connector Category: Repository and Event Mapper Connectors
- Hosting Service: Local OMRS Repository Connector
- Hosting Server: repository proxy
- Source Module: Hive Metastore Repository Connector
- Jar File Name:
egeria-connector-hivemetastore-1.1-SNAPSHOT.jar
Important notice
The gradle JAR step will include some of the dependencies into the connector JAR, making is a semi-Fat Jar. This makes sure that additional dependencies are automatically deployed together with the connector.
Configuration¶
Repository Proxy Connector embedded configuration¶
Configure a Repository proxy with an embedded native repository
Configure the event mapper connector¶
Any open metadata repository that supports its own API must also implement an event mapper to ensure the Open Metadata Repository Services (OMRS) is notified when metadata is added to the repository without going through the open metadata APIs.
The event mapper is a connector that listens for proprietary events from the repository and converts them into calls to the OMRS. The OMRS then distributes this new metadata.
For the Hive Metastore (HMS) Repository Proxy Connector this Event mapper currently polls for Hive Metastore content. It may be enhanced in the future to also emit granular events to track the HMS metadata as it changes.
POST - configure event mapper
{{platformURLRoot}}/open-metadata/admin-services/users/{{adminUserId}}/servers/{{serverName}}/local-repository/event-mapper-details?connectorProvider={{fullyQualifiedJavaClassName}}&eventSource={{resourceName}}
The connectorProvider should be set to the fully-qualified Java class name for the connector provider, and the eventSource should give the details for how to access the events (for example, the hostname and port number of an Apache Kafka bootstrap server).
HMS connector configuration overview¶
 HMS connector configuration overview
HMS connector configuration overview
Event mapper Endpoint address should be defined with the url of the thrift endpoint.
like this
"endpoint": {
"class": "Endpoint",
"address": "thrift://catalog.eu-de.dataengine.cloud.ibm.com:9083"
},
configurationProperties parameters
| Event mapper configuration parameter name | default | Description |
|---|---|---|
| qualifiedNamePrefix | empty string | This is a prefix for the qualifiedName. This prefix is used on every entity that is created using this connector. |
| refreshTimeInterval | null | Poll interval in minutes. If null only poll once at connector start time. |
| CatalogName | null | This is the HMS catalog name. |
| DatabaseName | null | This is the HMS database name. |
| sendPollEvents | true | Set this to true to send events to the cohort every poll. |
| endpointAddress | null | url to access the data that this metadata describes |
| cacheIntoCachingRepository | true | Set this to false to not cache the metadata content |
| securedProperties | null | If securedProperties need to be sent on the Connection entity, specify as a json object, with string properties. |
| includeDeployedSchema | false | When set to true a DeployedDatabaseSchema entity is created between the Database and the database schema. Set this option if you know that members of the cohort expect to see a DeployedDatabaseSchema |
Setting CatalogName and DatabaseName¶
The setting of these 2 parameters dictates the scope of metadata that is ingested from HMS. For Hive the default catalog name is hive and default database name is default.
| CatalogName | DatabaseName | scope of HMS content to be ingested |
|---|---|---|
| Name of a catalog | Name of a database | The HMS tables under the named database in the named catalog |
| null | null | All tables in all databases under all catalogs. If the HMS implementation does not support getCatalogs API then an error will be issued and the connector stopped |
| null | Name of a database | All tables in default catalog under the named database. |
| Name of a catalog | null | The HMS tables under all the databases in the named catalog. |
Using with the IBM Cloud® Data Engine service.¶
To use this connector with IBM Cloud® Data Engine service, the code needs to be recompiled to bring in the IBM HMS Client library. To do this the property ibmhms in the gradle build; on the command line specify:
./gradlew build -Pibmhms
The following additional security parameters need to be specified in the configurationProperties as the IBM Hive-compatible client
uses a secure API to talk to the IBM Cloud®.
| Event mapper configuration parameter name | default | Description |
|---|---|---|
| MetadataStoreUserId | null | The Data Engine service crn. |
| MetadataStorePassword | null | The API key |
| useSSL | false | Set to true |
| CatalogName | null | set to "spark" |
| DatabaseName | null | Set to "default" |
Using with Hive Metastore version 4.¶
At the time of writing the latest HMS version 4 client is 4.0.0-alpha-2. This client is required to communicate with the HMS server 4.0.0-alpha-2. To build with this HMS 4.0.0-alpha-2 client specify property hmsv4 in the gradle build; on the command line specify:
./gradlew build -Phmsv4
The logic to extract the columns for the HMS Table.¶
The IBM Cloud® Data Engine has HMS tables that describe IBM Cloud® object storage data. In this case the HMS table is an external table. In this case, the columns are described in HMS table parameters in an Apache Spark™ format.
For external tables (currently only verified using IBM Cloud® Data Engine service) the HMS connector.
1) Checks table parameter spark.sql.sources.schema.numParts. If specified then this is the number of spark sql sources schema parts that are present. Thre
schema parts are spark.sql.sources.schema.part.0 ...spark.sql.sources.schema.part.n - where n is one less than the number of parts. The
HMS connector stitches these parts together to form valid json and then extracts the column information from that json. This is a Spark v2 format.
2) If spark.sql.sources.schema.numParts is not specified, then the HMS connector extracts the columns from spark.sql.sources.schema. This is a Spark v3 format.
For all other cases and for external tables with spark.sql.sources.schema.numParts and spark.sql.sources.schema, the code looks in the
HMS table storage descriptor cols property to get the columns.
We can imagine that other scenarios might require the above logic to be amended. For example, for data stored in HDFS an exposed as a managed table then and using Spark data sources. If new scenarios occur, that can be tested by the community, then the above code can be extended.
Design¶
Components¶
The high level architecture of the connector is:
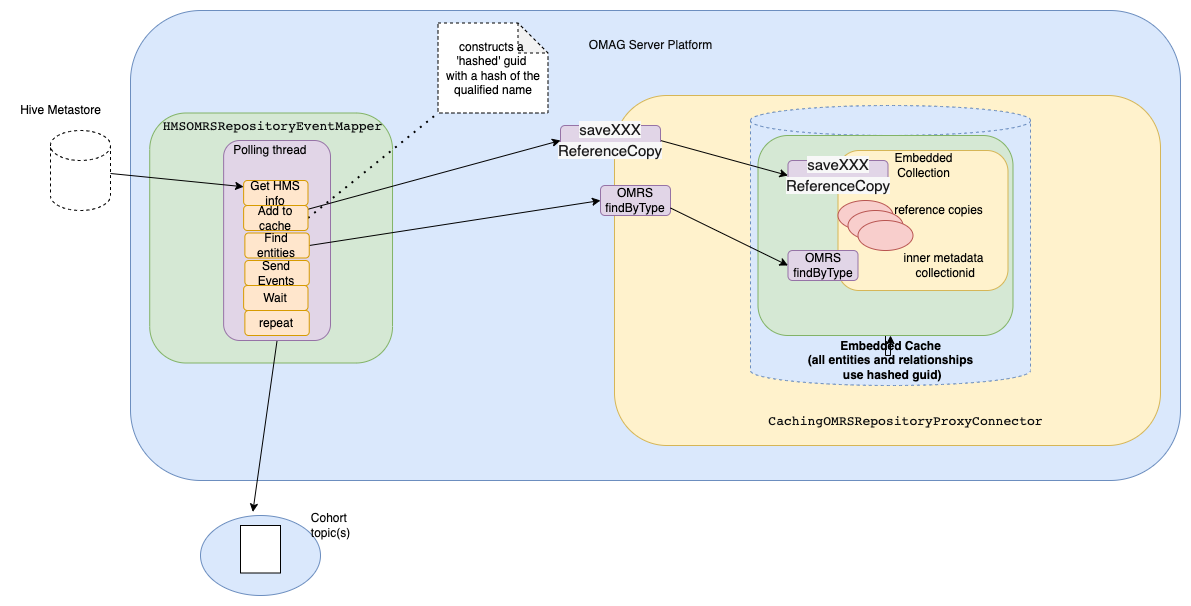
It shows how the event mapper polling loop:
- Gets the Hive metastore information from the Hive metastore.
- Adds the appropriate reference entities and relationships to the repository connector
- Finds the entities and relationships per asset (Database)
- Sends a batched event per asset
- Waits for the length of time specified in the refreshTimeInterval configuration parameter.
- repeats
Working with Hive Metastore and its APIs.¶
The Hive Metastore can be run as a standalone one. This standalone server jar file is also required for the Client API. The HMSClient API used is https://github.com/apache/hive/blob/master/standalone-metastore/metastore-common/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStoreClient.java It uses the Thrift API to communicate with the Hive Metastore. At this time (July 2022) the version 3.1.3 of this Hive Metastore has vulnerabilities A number of excludes were required in the gradle build file to ensure the inappropriate vulnerable libraries are not present - as reported by Sonarscan and Lift.
HMS Client calls used:
| HMS Client call | Description |
|---|---|
| client.getCatalogs() | Get all the catalog names |
| client.getAllDatabases() | Get all the database names under the default Catalog. |
| client.getAllDatabases(<catName>); | Get all the database names under the named Catalog. |
| client.getTables(<catName>, "*") | Get all the tables from the Catalog with name <catName> and database with name <dbName> |
| client.getTable(<catName>, <dbName>, <tableName>) | Get the table details for table named <tableName> in Catalog <catName>, the returned table contains the column details |
Hive Metastore mapping to Egeria OMRS open types¶
Egeria has an open type called Database we are mapping this to the Hive Database. Note that at Hive 3 there are higher level concepts called catalogs that hold databases.
Entity Types¶
| HMS concept | Description | Egeria open Entity type | Comments |
|---|---|---|---|
| Catalog | Higher level of container within Hive | Not modeled | The getCatalogs API is not always present in all HMS implementations |
| Database | Lives within a Catalog | Database | |
| n/a | n/a | Connection | This represents the connection to the instance data |
| n/a | n/a | ConnectionType | This is the type of the connection |
| n/a | n/a | Endpoint | This is where the endpoint information is stored |
| n/a | n/a | DeployedDatabaseSchema | Deployed Schema |
| n/a | n/a | RelationalDBSchemaType | Database schema type |
| Table | Lives within a Catalog | RelationalTable | Relational Table |
| Column | Lives within a Catalog | RelationalColumn | Relational Column |
Relationship Types¶
| Egeria open Relationship type | Comments |
|---|---|
| ConnectionEndpoint | Relationship between Connection and Endpoint |
| ConnectionConnectorType | Relationship between Connection and Connector Type |
| ConnectionToAsset | Relationship between Connection and Asset |
| AssetSchemaType | Relationship between Database (the asset) and Schema Type |
| AttributeForSchema | Relationship between the RelationalTable and RelationalColumn |
| DataSetContent | Relationship between DeployedDatabaseSchema and RelationalDBSchemaType |
Classification Types¶
| HMS concept | Description | Egeria open Classification type | Comments |
|---|---|---|---|
| Hive table Type | if this is VIRTUAL_VIEW then this is a view rather than a table | CalculatedValue | The RelationalTable is classified with CalculatedValue for a view |
| for columns fieldSchema Type | This is the type of the Hive column (e.g. String) | TypeEmbeddedAttribute | This contains the type of the column |
| for tables n/a | n/a | TypeEmbeddedAttribute | The type of the Table |
Using with the Hive Metastore listener¶
The Hive metastore listener runs in the HMS process as a HMS listener. When HMS tables are added, dropped or altered then appropriate Egeria events are issued. It sends the 'granular events. In this way the Egeria cohort members are kept up to date as the HMS metadata changes.
The HMS connector needs to have run prior to the listener, so that the Egeria cohort already has existing entities that the HMS tables can be associated with. The listener needs to be configured as the same cohort member as the connector.
| HMS configuration parameter | Description |
|---|---|
| EgeriaListener.metadataCollectionId | This is the metadata collection id of the HMS connector |
| EgeriaListener.serverName | This is the server name of the HMS connector |
| EgeriaListener.organisationName | Organisation name to match the HMS connector |
| EgeriaListener.qualifiedNamePrefix | Qualified name prefix the HMS connector |
| EgeriaListener.events.kafka.topicname | The cohort topic name that the HMS connector writes to |
| EgeriaListener.events.kafka.clientId | The client ID of the HMS connector |
| EgeriaListener.events.kafka.bootstrapServerurl | The bootstrap server name for the Kafka defined for the HMS connector |
You may also find these links in the Egeria documentation useful:
During 2022 we have also had a number of Webinars relating to connector choices and design:
Reference materials¶
- https://github.com/odpi/egeria/blob/master/open-metadata-implementation/repository-services/README.md and it's sub-pages are great resources for developers.
- Egeria Webinars particularly the one on repository connectors.
License: CC BY 4.0, Copyright Contributors to the ODPi Egeria project.